汇总整理自《不可思议的Word2Vec》系列,作者苏剑林。部分内容有删改。
对于了解深度学习、自然语言处理 NLP 的读者来说,Word2Vec 可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google 出品的高效率的获取词向量的工具。
Word2Vec 的数学原理
Word2Vec 不可思议?
大多数人都是将 Word2Vec 作为获取词向量的工具,而关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec 实在是太粗糙了。但是抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec 的两个模型 —— CBOW 和 Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的 NLP 任务,都是建立在这个关系之上。
说到 Word2Vec 的“不可思议”,在 Word2Vec 发布之初,可能最让人惊讶的是它的 Word Analogy 特性,即诸如 king - man ≈ queen - woman 的线性特性,而发布者 Mikolov 认为这个特性意味着 Word2Vec 所生成的词向量具有了语义推理能力,而正是因为这个特性,加上 Google 的光环,让Word2Vec迅速火了起来。但很遗憾,我们自己去训练词向量的时候,其实很难复现这个结果出来,甚至也没有任何合理的依据表明一份好的词向量应该满足这个 Word Analogy 特性。
数学原理:网络资源
有心想了解这个系列的读者,有必要了解一下 Word2Vec 的数学原理。当然,Word2Vec 出来已经有好几年了,介绍它的文章数不胜数,这里我推荐 peghoty 大神的系列博客:word2vec 中的数学原理详解。另外,本文作者的博文《词向量与Embedding究竟是怎么回事?》也有助于我们理解 Word2Vec 的原理。
为了方便读者阅读,我还收集了两个对应的 PDF 文件:
其中第一个就是推荐的 peghoty 大神的系列博客的 PDF 版本。当然,英文好的话,可以直接看 Word2Vec 的原始论文:
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
但个人感觉,原始论文并没有中文解释得清晰。
数学原理:简单解释
简单来说,Word2Vec 就是“两个训练方案+两个提速手段”,所以严格来讲,它有四个备选的模型。两个训练方案分别是 CBOW 和 Skip-Gram,如下图所示:
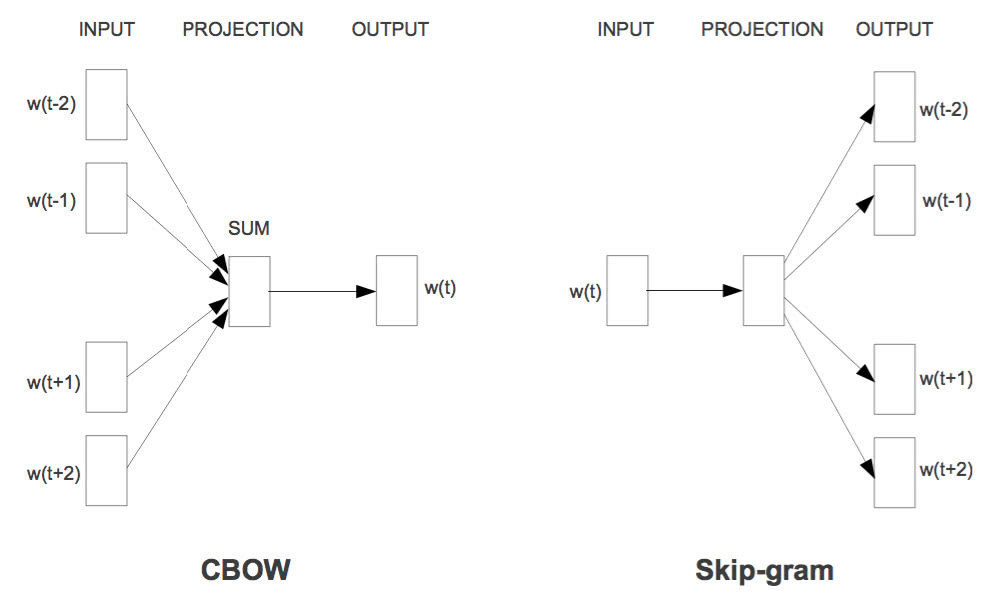
两个训练方案用通俗的语言来说,就是“周围词叠加起来预测当前词”($P(w_t|Context)$)和“当前词分别来预测周围词”($P(w_{others}|w_t)$),也就是条件概率建模问题了;两个提速手段,分别是层次 Softmax 和负样本采样。层次 Softmax 是对 Softmax 的简化,直接将预测概率的复杂度从 $\mathscr{O}(|V|)$ 降为 $\mathscr{O}(\log_2 |V|)$,但相对来说,精度会比原生的 Softmax 略差;负样本采样则采用了相反的思路,它把原来的输入和输出联合起来当作输入,然后做一个二分类来打分,这样子我们可以看成是联合概率 $P(w_t,Context)$ 和 $P(w_{others},w_t)$ 的建模了,正样本就用语料出现过的,负样本就随机抽若干。更多的内容还是去细看 peghoty 大神的系列博客比较好。
本系列所使用的模型是“Skip-Gram + 层次 Softmax”的组合,也就是要用到 $P(w_{others}|w_t)$ 这个模型的本身,而不仅仅是词向量。所以,要接着看本系列的读者,需要对 Skip-Gram 模型有些了解,并且对层次 Softmax 的构造和实现方式有些印象。
训练好的模型
由于后面要讲解 Word2Vec 怎么用,因此笔者先训练好了一个 Word2Vec 模型,用 Gensim 训练。单纯的词向量并不大,但前面已经说了,我们要用到完整的 Word2Vec 模型,因此我将完整的模型分享出来了,包含四个文件,所以文件相对大一些。
链接: https://pan.baidu.com/s/1dF7oTH3 密码: uw4r
包含文件:word2vec_wx、word2vec_wx.syn1neg.npy、word2vec_wx.syn1.npy 和 word2vec_wx.wv.syn0.npy,4 个文件都是 Gensim 加载模型所必需的。具体每个文件的含义我也没弄清楚,word2vec_wx 大概是模型声明,word2vec_wx.wv.syn0.npy 应该就是我们所说的词向量表,word2vec_wx.syn1.npy 是隐层到输出层的参数(Huffman 树的参数),word2vec_wx.syn1neg.npy 就不大清楚了~
如果你只关心词向量,也可以下载 C 版本的格式(跟 C 版本 Word2Vec 兼容,只包含词向量): 链接: https://pan.baidu.com/s/1nv3ANLB 密码: dgfw
提醒读者的是,如果你想获取完整的 Word2Vec 模型,又不想改源代码,那么 Python 的 Gensim 库应该是你唯一的选择,据我所知,其他版本的 Word2Vec 最后都是只提供词向量给我们,没有完整的模型。
模型概况
这个模型的大概情况如下:
\[\begin{array}{c|c} \hline \text{训练语料} & \text{微信公众号的文章,多领域,属于中文平衡语料}\\ \hline \text{语料数量} & \text{800 万篇,总词数达到 650 亿}\\ \hline \text{模型词数} & \text{共 352196 词,基本是中文词,包含常见英文词}\\ \hline \text{模型结构} & \text{Skip-Gram + Huffman Softmax}\\ \hline \text{向量维度} & \text{256 维}\\ \hline \text{分词工具} & \text{结巴分词,加入了有 50 万词条的词典,关闭了新词发现}\\ \hline \text{训练工具} & \text{Gensim 的 Word2Vec,服务器训练了 7 天}\\ \hline \text{其他情况} & \text{窗口大小为 10,最小词频是 64,迭代了 10 次}\\ \hline \end{array}\]公众号文章属于比较“现代”的文章,反映了近来的网络热点内容,覆盖面也比较广,因此文章相对来说还是比较典型的。对于分词,我用的是结巴分词,并且关闭了新词发现,这是宁可分少一些,也要分准一些。当然,自带的词典是不够的,笔者自己还整理了 50 万词条,词条来源有两部分:1、网络收集的词典合并;2、在公众号文章上做新词发现,人工筛选后加入到词典中。因此,分词的结果还算靠谱,而且包含了比较多的流行词,可用性较高。
训练代码
大家可以参考着改写,要注意,这里引入 hashlib.md5 是为了对文章进行去重(本来 1000 万篇文章,去重后得到 800 万),而这个步骤不是必要的。
#! -*- coding:utf-8 -*-
import gensim, logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
import pymongo
import hashlib
db = pymongo.MongoClient('172.16.0.101').weixin.text_articles_words
md5 = lambda s: hashlib.md5(s).hexdigest()
class sentences:
def __iter__(self):
texts_set = set()
for a in db.find(no_cursor_timeout=True):
if md5(a['text'].encode('utf-8')) in texts_set:
continue
else:
texts_set.add(md5(a['text'].encode('utf-8')))
yield a['words']
print u'最终计算了%s篇文章'%len(texts_set)
word2vec = gensim.models.word2vec.Word2Vec(sentences(), size=256, window=10, min_count=64, sg=1, hs=1, iter=10, workers=25)
word2vec.save('word2vec_wx')
一些演示
主要随便演示一下该模型找近义词的结果。
>>> import gensim
>>> model = gensim.models.Word2Vec.load('word2vec_wx')
>>> pd.Series(model.most_similar(u'微信'))
0 (QQ, 0.752506196499)
1 (订阅号, 0.714340209961)
2 (QQ号, 0.695577561855)
3 (扫一扫, 0.695488214493)
4 (微信公众号, 0.694692015648)
5 (私聊, 0.681655049324)
6 (微信公众平台, 0.674170553684)
7 (私信, 0.65382117033)
8 (微信平台, 0.65175652504)
9 (官方, 0.643620729446)
>>> pd.Series(model.most_similar(u'广州'))
0 (东莞, 0.840889930725)
1 (深圳, 0.799216389656)
2 (佛山, 0.786817133427)
3 (惠州, 0.779960036278)
4 (珠海, 0.73523247242)
5 (厦门, 0.72509008646)
6 (武汉, 0.724122405052)
7 (汕头, 0.719602584839)
8 (增城, 0.713532209396)
9 (上海, 0.710560560226)
>>> pd.Series(model.most_similar(u'微积分'))
0 (线性代数, 0.808522999287)
1 (数学分析, 0.791161835194)
2 (高等数学, 0.786414265633)
3 (数学, 0.758676528931)
4 (概率论, 0.747221827507)
5 (高等代数, 0.737897276878)
6 (解析几何, 0.730488717556)
7 (复变函数, 0.715447306633)
8 (微分方程, 0.71503329277)
9 (微积分学, 0.704192101955)
汇总整理自《不可思议的Word2Vec》系列,作者苏剑林。部分内容有删改。