本文魔改自《依存句法分析在深度学习中的应用》,原作者:何晗
句法分析是一项核心的 NLP 任务,目标是获取句子的主谓宾等句法结构。在传统机器学习方法中,我们通常是在给定的依存句法树上,利用规则手工提取句法树的特征。随着神经网络方法的兴起,这种特征工程方法已经不再适用,那么我们应该如何提取树的向量表示呢?本文简单地通过 7 种模型来介绍依存句法分析在深度学习中的应用,涵盖 Tree-LSTM、DCNN 和 GCN 等。
Tree-LSTM
最著名的方法当属 Tree-LSTM (Tai et al., 2015),它扩展了经典的 LSTM 模型,使得原本的序列化模型可以处理树形结构。下图中左边就是标准的线性结构 LSTM,右边就是树形结构 LSTM。
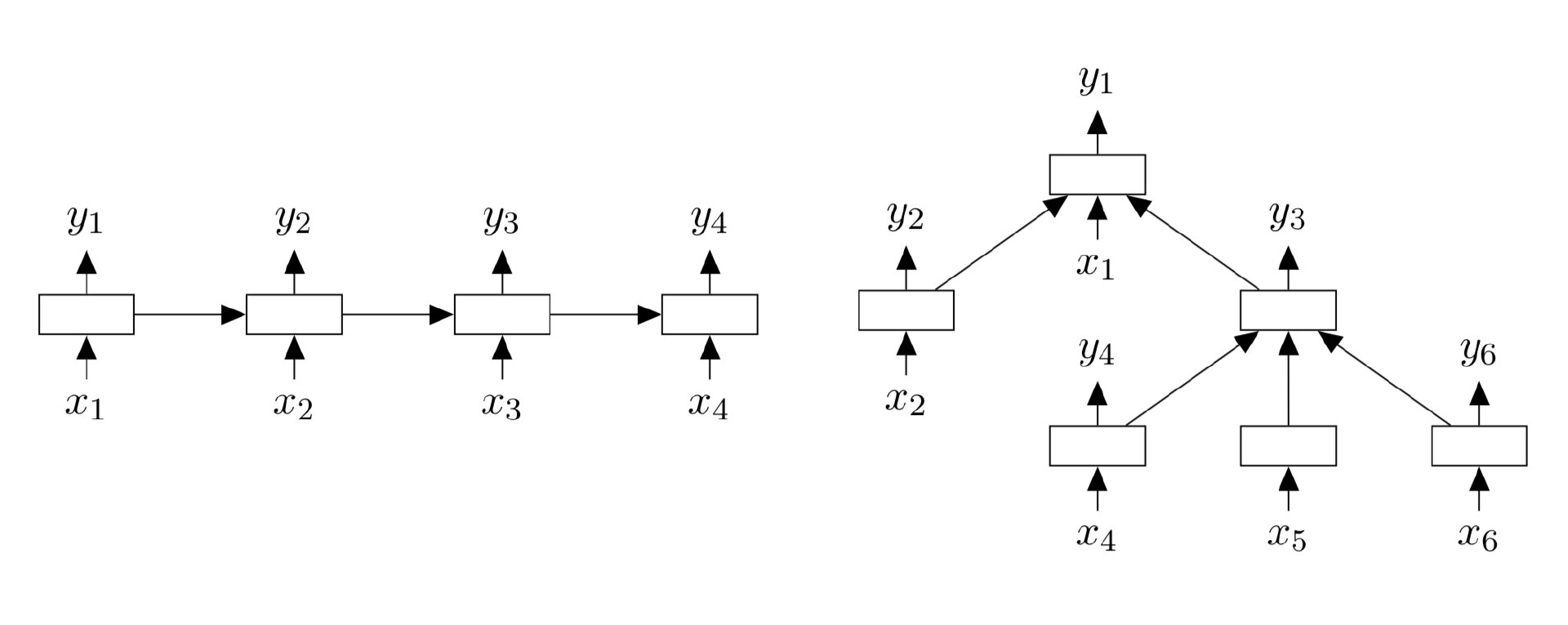
与标准的 LSTM 单元类似,每个 Tree-LSTM 单元 $j$ 包含输入和输出门 $i_j$ 和 $o_j$,一个记忆单元 $c_j$ 和隐藏状态 $h_j$。不同的是,Tree-LSTM 单元中的门控向量和记忆单元的更新依赖于子单元的状态,而且 Tree-LSTM 单元对每一个孩子 $k$ 都有一个遗忘门 $f_{jk}$。
Tree-LSTM 有 Child-Sum 和 $N$-ary 两种结构,这两种结构都使得每个 LSTM 单元可以合并多个孩子节点的信息。
Child-Sum Tree-LSTM
给定一棵树,假设 $C(j)$ 表示节点 $j$ 的孩子集合,Child-Sum Tree-LSTM 就可以表示为:
\[\begin{align} {\tilde h_j} &= \sum_{k \in C\left( j \right)} \\ i_j &=\sigma \left( W^{(i)} x_j + U^{(i)} {\tilde h_j} + b^{(i)} \right)\\ f_{jk} &= \sigma\left( W^{(f)} x_j + U^{(f)} h_{k} + b^{(f)} \right)\\ o_j &= \sigma \left( W^{(o)} x_j + U^{(o)} {\tilde h_j} + b^{(o)} \right)\\ u_j &= \tanh\left( W^{(u)} x_j + U^{(u)} {\tilde h_j} + b^{(u)} \right)\\ c_j &= i_j \odot u_j + \sum_{k \in C(j)} f_{jk} \odot c_{k}\\ h_j &= o_j \odot \tanh(c_j) \end{align}\]由于 Child-Sum Tree-LSTM 每一个单元都是通过其子节点隐藏状态 $h_k$ 的求和 ${\tilde h_j}$ 来计算,因此它非常适用于子节点数目很多且无序的树,比如依存句法树,它每一个 head 的依存节点数可以变化很大。
$N$-ary Tree-LSTM
当子节点最多为 $N$ 并且有序时(例如可以编号为 $1$ 到 $N$),可以使用 $N$-ary Tree-LSTM。对于每一个节点 $j$,我们分别使用 $h_{jk}$ 和 $c_{jk}$ 来表示它的第 $k$ 个子节点的隐状态和记忆单元,$N$-ary Tree-LSTM 就可以表示为:
\[\begin{align} i_j &=\sigma \left( W^{(i)} x_j + \sum_{\ell=1}^N U^{(i)}_\ell h_{j\ell} + b^{(i)} \right)\\ f_{jk} &= \sigma\left( W^{(f)} x_j + \sum_{\ell=1}^N U^{(f)}_{k\ell} h_{j\ell} + b^{(f)} \right)\\ o_j &= \sigma \left( W^{(o)} x_j + \sum_{\ell=1}^N U^{(o)}_\ell h_{j\ell} + b^{(o)} \right)\\ u_j &= \tanh\left( W^{(u)} x_j + \sum_{\ell=1}^N U^{(u)}_\ell h_{j\ell} + b^{(u)} \right) \\ c_j &= i_j \odot u_j + \sum_{\ell=1}^N f_{j\ell} \odot c_{j\ell}\\ h_j &= o_j \odot \tanh(c_j) \end{align}\]可以看到,当树没有子节点,只是一条链时,模型就退化为标准的 LSTM。
DCNN
前面我们通过 Tree-LSTM 模型介绍了如何改造经典的 RNN 模型,使它可以处理树形结构的数据。下面我们将注意力转向另一个在 NLP 领域应用广泛的模型 CNN,看看如何将 CNN 用于树形结构数据。
DCNN (Dependency-based CNN) 由 Ma et al. (2015) 提出,与 Kim et al. (2014) 直接将文本中的词语按顺序输入不同,DCNN 还考虑了每一个词语在依存树上的父节点、祖父节点、曾祖父节点和兄弟节点,因此可以捕获到无法直接从文本表面获得的远程依赖。
序列卷积
一般 NLP 中的 CNN 按照序列顺序在词语序列上进行一维卷积:
\[\begin{equation} \widetilde{ \bf x}_{i,j} = {\bf x}_i \oplus {\bf x}_{i+1}\oplus \cdots \oplus {\bf x}_{i+j} \end{equation}\]${\bf x}_i$ 是句子中的第 $i$ 个词语,$\oplus$ 是连接运算符。序列词语连接 $\widetilde{ \bf x}_{i,j}$ 就像一个 n-gram 模型,它连接第 $i$ 个词到第 $i+j$ 个词语的词向量,然后将局部信息输入到卷积操作中。但是除非扩大滑动窗口,否则模型难以捕获到远距离依赖,而如果扩大窗口又会造成数据稀疏问题。
因此 DCNN 做了 2 种简单的改进,即基于祖先路径卷积和基于兄弟节点卷积,如下图所示:
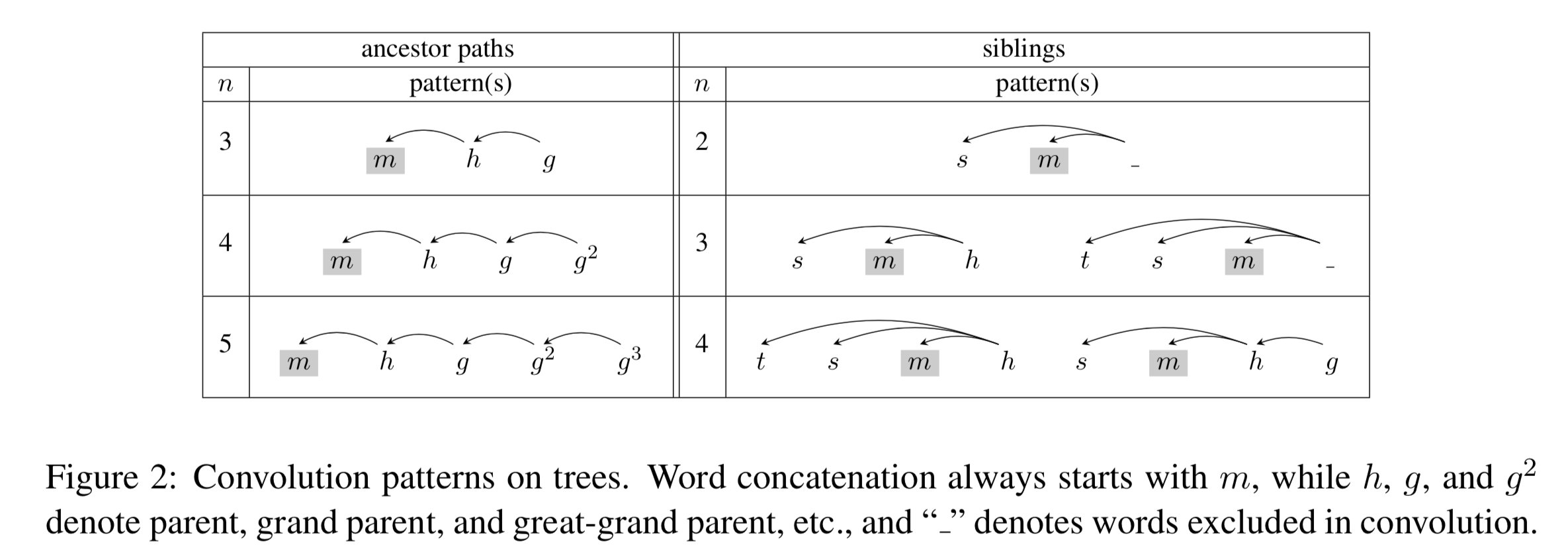
左边是基于祖先路径卷积,右边是基于兄弟节点卷积。词语连接始终从 $m$ 开始,$h$、$g$ 和 $g^2$ 分别表示父节点、祖父节点和曾祖父节点,_ 表示卷积中忽略的词语。
基于祖先路径卷积
先来看基于祖先路径卷积,它基于给定的词语 ${\bf x}_i$ 的依存树进行连接:
\[\begin{equation} {\bf x}_{i,k} = {\bf x}_{i} \oplus {\bf x}_{p(i)}\oplus \cdots \oplus {\bf x}_{p^{k-1}(i)} \end{equation}\]其中,$p^k(i)$ 返回单词 $i$ 的第 $k$ 个祖先,由如下公式递归定义:
\[\begin{equation} p^k(i)= \begin{cases} p(p^{k-1}(i)) & \text{if} \quad k>0 \\ i & \text{if} \quad k=0 \\ \end{cases} \end{equation}\]卷积操作从 ${\bf x}_i$ 开始,并连接它的祖先:
\[c_i= f(\mathbf w \cdot {\bf x}_{i,k} + b)\]并且如果到达根节点,则添加“Root”作为虚拟祖先节点。对于每一个词语序列 ${\bf x}_{i,k}$,卷积核 ${\bf w} \in \mathbb{R}^{k \times d}$ 都会得到 feature map ${\bf c} \in \mathbb{R}^l$,其中 $l$ 是句子长度:
\[{\bf c} = [c_1, c_2, ...,c_l]\]基于兄弟节点卷积
也就是将兄弟节点拼接起来做卷积,有时候也将父节点拼接起来。如上图右侧所示。
混合模型
树形结构信息虽然有用,但它无法完全覆盖原始文本的序列信息。而且如果依存树解析有误,还会引入额外的误差,但是连续的 n-gram 信息是永远不会出错的,因此序列卷积、祖先路径卷积、兄弟节点卷积各有千秋,最好把它们结合起来。一个简单的方法是将它们产生的 feature map 都拼接起来,作为最终的句子表示:
\[\hat{\bf c} = [\underbrace{\hat{c}_a^{(1)}, …, \hat{c}_a^{(N_a)}}_\text{ancestors}; \underbrace{\hat{c}_s^{(1)}, …, \hat{c}_s^{(N_s)}}_\text{siblings}; \underbrace{\hat{c}^{(1)}, …, \hat{c}^{(N)}}_\text{sequential}]\]其中 $N_a$、$N_s$、$N$ 分别是是基于祖先路径卷积、基于兄弟节点卷积和序列卷积的卷积核的数量。
最短路径
编码依存句法树中主体 S 和客体 O 之间的最短依存路径也是神经网络方法中常见的用法,因为最短依存路径只专注于两个实体之间的相关信息,从而可以过滤掉一些无用的噪声。
SDP-LSTM
比如用于识别句子中两个实体之间关系的 SDP-LSTM (Xu et al., 2015) 模型,它将两个实体之间最短依存路径上的单词按顺序用 LSTM 过一遍:
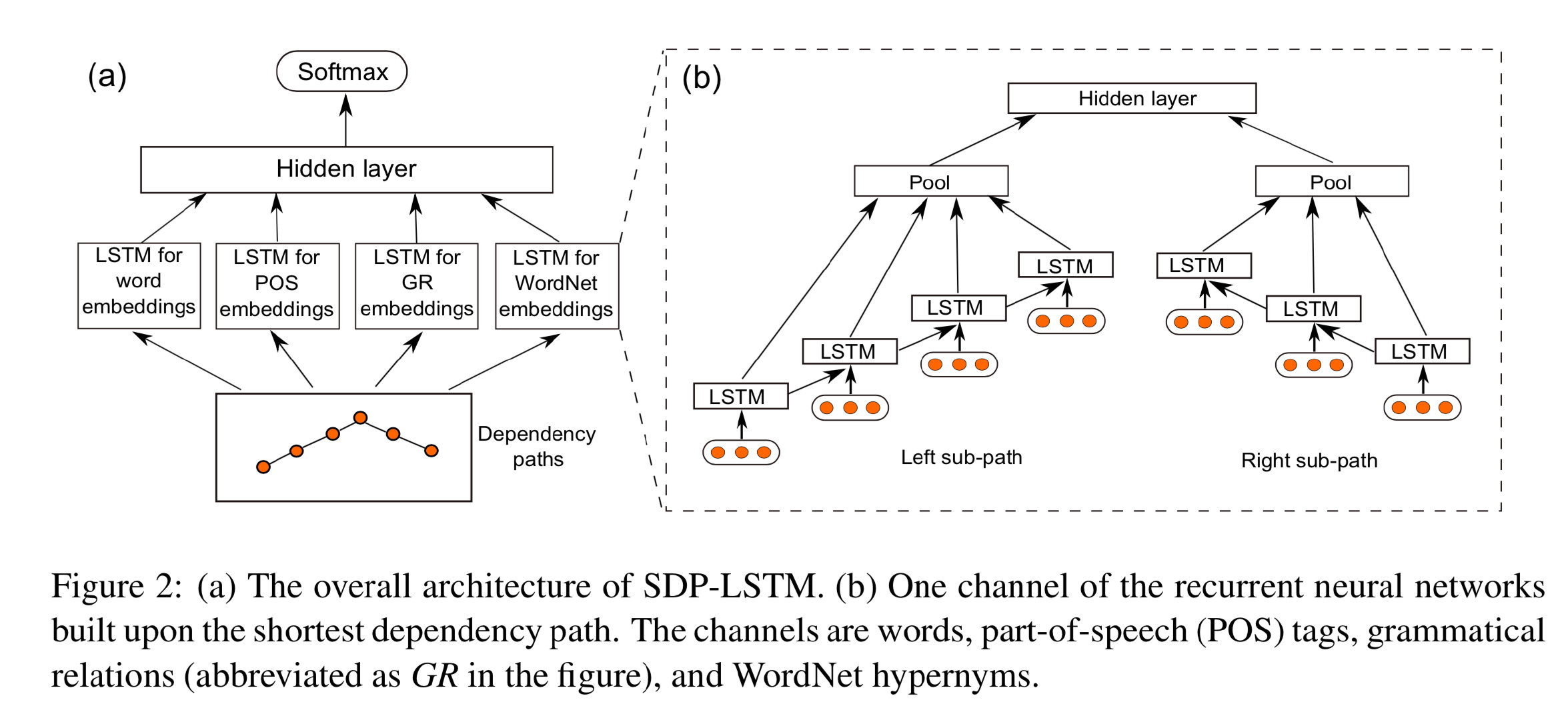
两个 LSTM(图2b)分别捕获最短依存路径 SDP 的左右子路径上的信息(该路径由两个实体的公共祖先节点分隔),然后通过池化操作得到每个路径上 LSTM 捕获到的信息。
BRCNN
另一个经典的模型是 BRCNN (Cai et al., 2016),它尝试通过结合 CNN 和 LSTM 模型来充分捕获最短依存路径中的依存信息。实际做法也很简单粗暴,就是首先用 BiLSTM 将最短依存路径正反过两遍,然后在上层用 CNN 来提取局部(相邻的两个词语以及它们之间的依存关系)特征,最后再通过最大池化操作来提取特征。如下图所示:
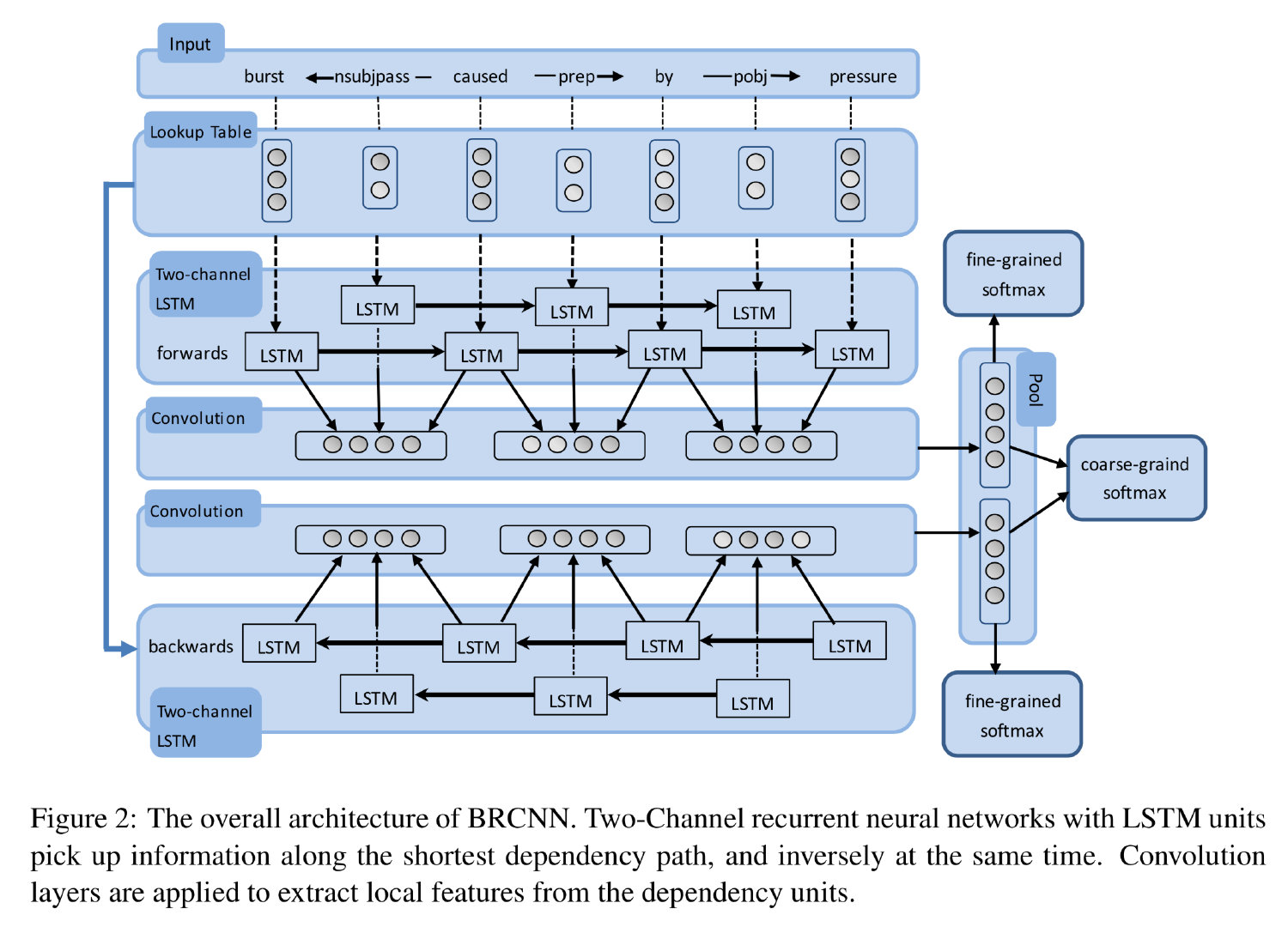
注意这里的 BiLSTM 与常规的不同,它有一个方向是在依存关系标签上运行的。
DepNN
本文开头介绍的 Tree-LSTM 和 DCNN 模型分别是 RNN 和 CNN 建模树形结构的早期代表作,DepNN (Liu et al., 2015) 则进一步探索了如何通过结合最短依存路径和子树来充分使用依存信息。
Augmented Dependency Path
之前的工作表明,实体之间的依存信息对于实体关系识别是有帮助的,其中最常用的就是最短依存路径和依存子树。因此,作者尝试将这两种信息合并起来考虑,提出了新的结构,称为 Augmented Dependency Path (ADP) 它在最短依赖路径上将依赖子树附加到单词上,如下图所示。
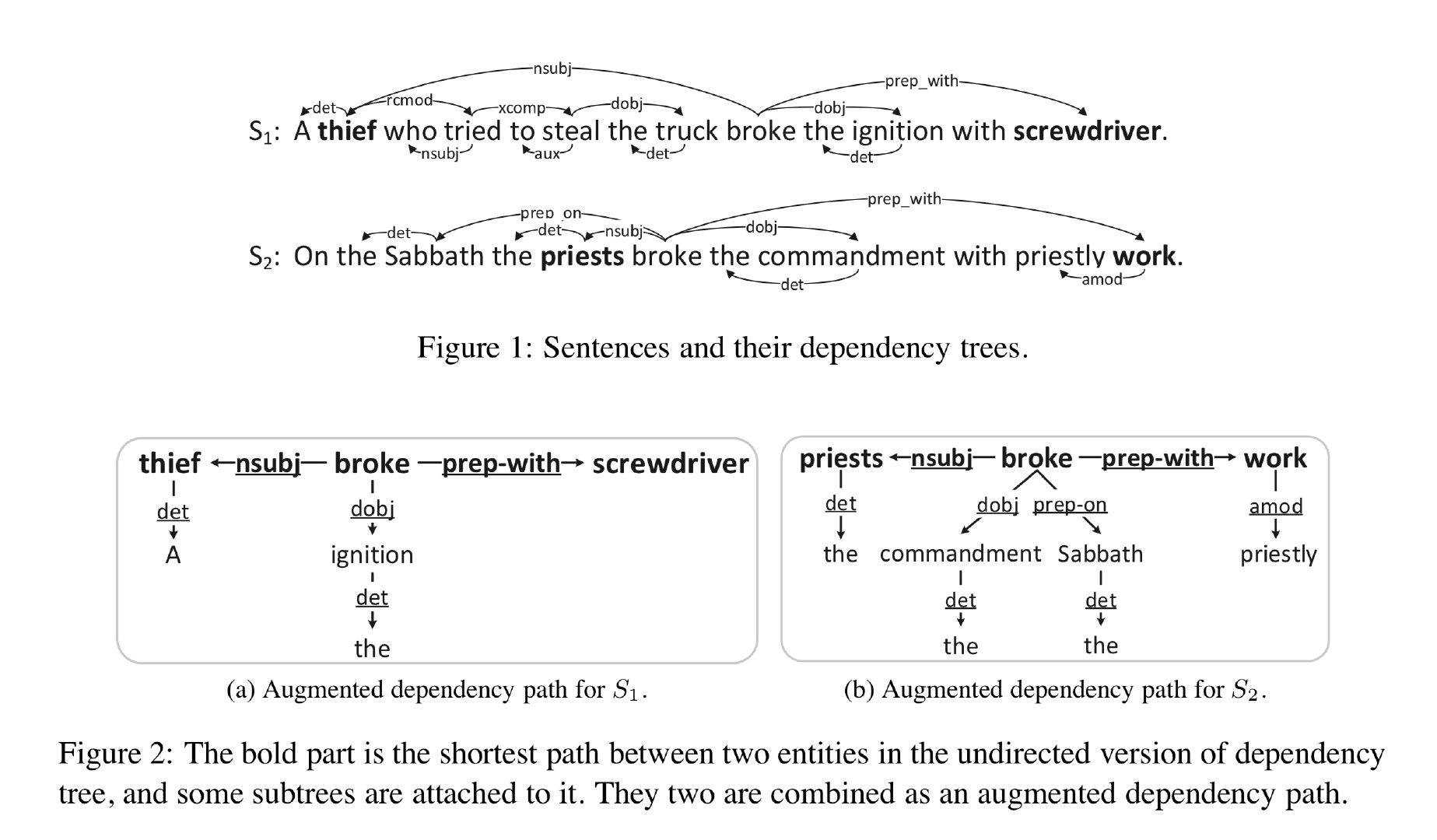
之前大部分的工作都专注于使用最短依存路径而忽视连接到节点上子树,这是有缺陷的,例如上图中的这两个句子,它们属于不同的关系类别,但是最短依存路径(加粗)却是类似的。而这种情况通过子树就可以进行区分,例如上图中的“dobj→commandment”和“dobj→ignition”。
DepNN
那么接下来就是考虑如何通过模型来捕获 ADP 上的信息了。为此,论文提出了 Dependency-Based Neural Networks (DepNN) 模型,它首先利用 RNN 基于每一个词语的依存子树来对其进行建模,然后再利用 CNN 在最短依存路径上提取特征。如下图所示:
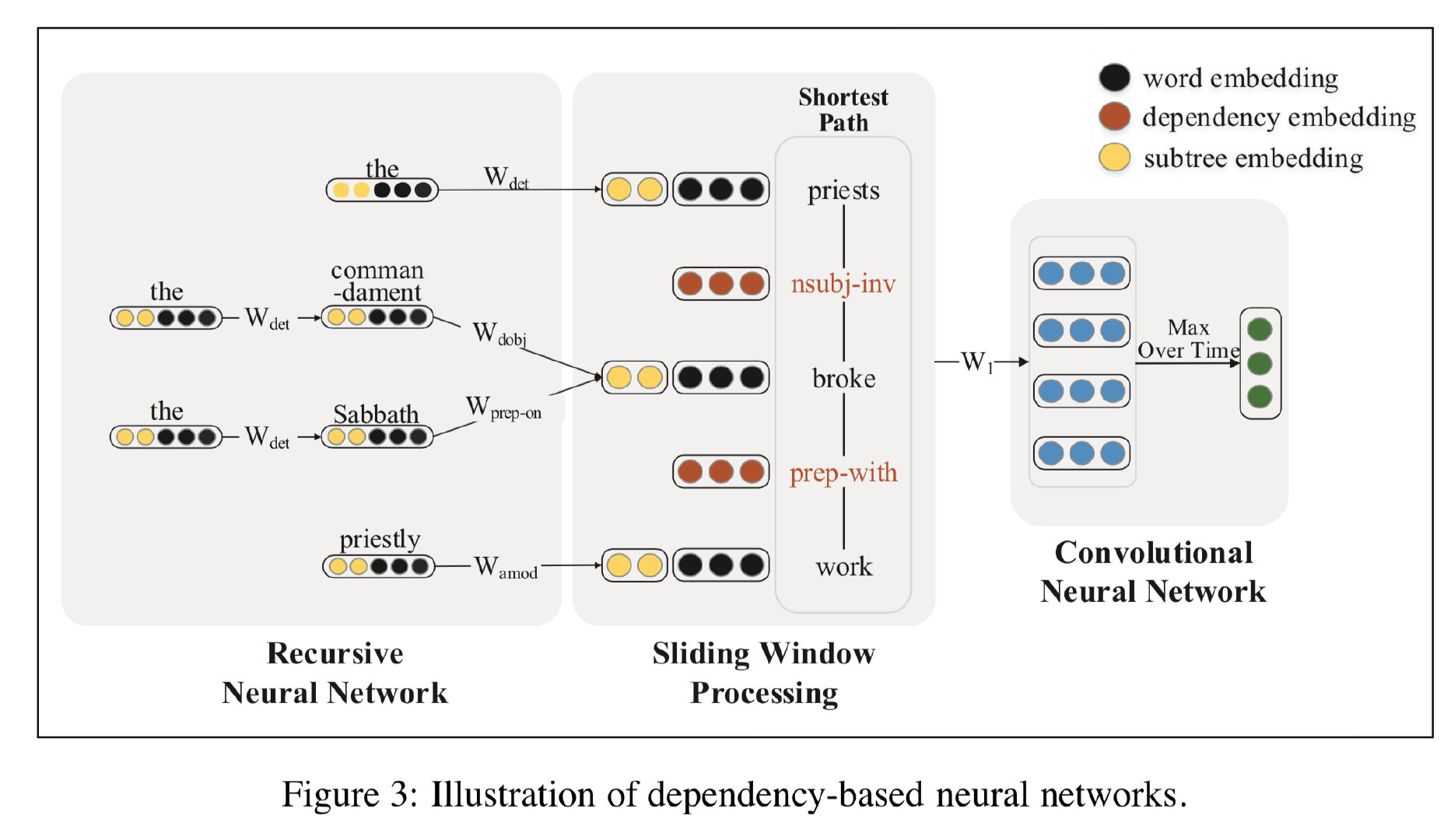
具体来说,对于最短依存路径中的每一个词语 $w$,模型首先采用 LSTM 编码其对应的子树(从叶子节点到根节点),并且将子树编码 $\boldsymbol{c}_w$ 和词语自身词向量 $\boldsymbol{x}_w$ 相连接作为词语 $w$ 的最终编码。然后,在词语和依存关系表示的基础上,采用 CNN 来编码最短依存路径。
GCN
可以看到上述基于依存树的模型,要么通过修剪依存树(只挑选最短依存路径)而丢弃了许多重要的信息,要么由于难以在不同的树结构上并行化而使得计算效率低下。而且 Zhang et al. (2018) 指出,直接使用最短依存路径是存在缺陷的,有时候一些很关键的虚词(否定词)不一定在两个实体的最短依存路径上,比如:

所以作者提出要考虑一些路径之外的词语,所使用的模型就是 GCN。即首先通过图卷积运算对输入句子的依存结构进行编码,然后提取以实体为中心的表示来判断实体之间的关系。
Graph Convolutional Networks
GCN (Kipf and Welling, 2017) 是一种编码图数据的网络结构,给定一个包含 $n$ 个节点的有向图,可以将其表示为$n\times n$ 的邻接矩阵 $\bf A$,其中 $A_{ij}=1$ 表示存在从 $i$ 到 $j$ 的边。在 $L$ 层的 GCN 中,如果我们记第 $l$ 层节点 $i$ 的输入向量为 $h^{(l−1)}_i$,输出向量为 $h^{(l)}_i$,那么,图卷积操作定义如下:
\[\begin{align} h_i^{(l)} = \sigma\big( \sum_{j=1}^n A_{ij} W^{(l)}{h}_j^{(l-1)} + b^{(l)} \big) \end{align}\]$A_{ij}$ 只在邻接节点处等于 1,所以图卷积实际上是让节点从自己的邻接节点处获取和汇总信息。
依存句法树上的 GCN
虽然树是图的子集,但这并不意味可以直接将 GCN 应用于依存句法树。首先,因为每个节点的出度相差巨大,这可能会使学习到的句子表示偏向于出度大的节点。其次,由于依存树中节点不会连接到自己,所以 $h^{(l−1)}_i$ 中的信息永远不会传递到 $h^{(l)}_i$。
为了解决这两个问题,作者提出先自加一个单位矩阵引入自我连接环,然后再归一化,即:
\[\begin{align} h_i^{(l)} =& \sigma\big( \sum_{j=1}^n \tilde{A}_{ij} W^{(l)}{h}_j^{(l-1)} / d_i + b^{(l)} \big) \end{align}\]其中,$\tilde{\bf A}=\bf{A} + {\bf I}$,$\bf I$ 是一个 $n \times n$ 的单位矩阵,$d_i=\sum_{j=1}^n \tilde{A}_{ij}$ 是节点 $i$ 的出度。GCN 在无标签句法树上的架构如下所示:
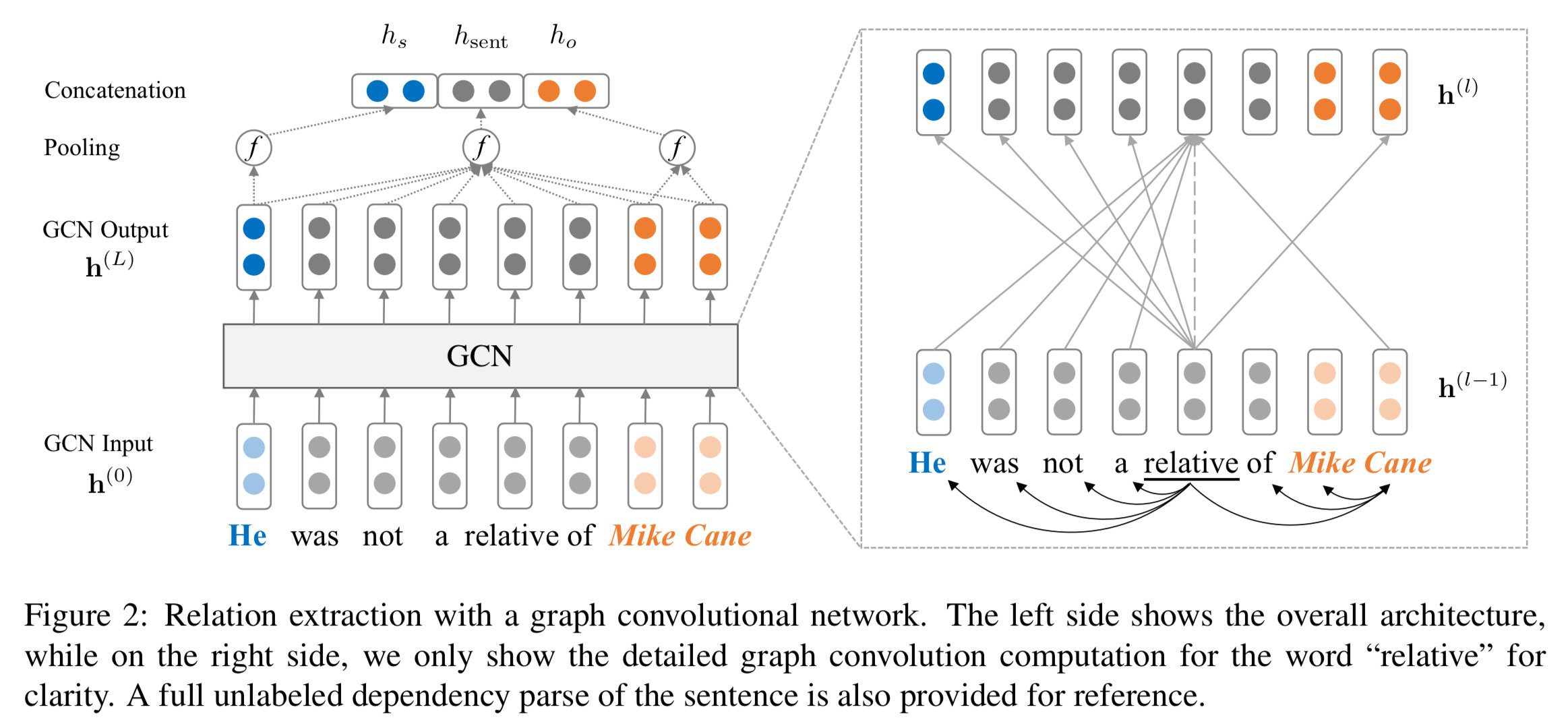
值得一提的是,作者发现在关系抽取任务中,将句法树视作无向图效果最好,包括对不同类型(topdown、bottom-up 和 self-loop)的边使用不同的转移矩阵 $W$、添加边相关的门控单元等操作都没有什么卵用:)。
Contextualized GCN
但是上述 GCN 中输入的词向量没有包含文本的上下文信息,而且 GCN 非常依赖于正确的句法树结构,错误解析的句法树还会引入额外的误差。为了解决这些问题,作者提出了 Contextualized GCN (C-GCN) 模型,先将词向量过一遍 BiLSTM 提取一下上下文信息再作为 $\bf h^{(0)}$ 输入网络。为了减小误差传播带来的影响,作者提出保留最短依存路径上每个节点 $K$ 条边以内的子树。作者的试验显示 $K=1$ 的效果最好,此时 Figure 1 里面的红色“not”被保留下来了。
soft pruning
如何从依存树上提取相关的信息,同时忽略无关信息一直是一个挑战。已有的方法大多是基于手工规则来提取依存结构,要么是保留所有,要么是取深度 $K$。为此 Guo et al. (2019) 提出了能够自动调节的 Attention Guided Graph Convolutional Networks (AGGCN),它可以被视作是一种树软修剪(soft-pruning)方法,以整棵依存树作为输入,通过模型自动地挑选对任务有帮助的相关结构。
事实上,前面我们介绍的 GCN 也可以看做是一种硬 Attention 机制,它直接基于邻接矩阵,对于那些不在提取出的子树上的节点,其所有边的权重都将直接被设为零,而这种做法可能会丢掉很多原始依存树中的相关信息。因此 AGGCN 采用了一种“软修剪”策略,通过 Attention 机制来为所有边分配权重。
具体来说,AGGCN 通过使用多头 self-attention 机制构建一个邻接矩阵 $\mathbf{\tilde{A}}$ 将原始的依存树转换成一个全连接图,并且每一个元素 $\mathbf{\tilde{A}}_{i,j}$ 表示从节点 $i$ 到 $j$ 的边的权重。其中第 $t$ 个头的 attention 邻接矩阵的计算方法如下:
\[\begin{equation} \mathbf{\tilde{A}^{(t)}} = softmax(\frac{Q\mathbf{W}_{i}^{Q} \times (K\mathbf{W}_{i}^{K})^{T}}{\sqrt{d}}) \end{equation}\]其中,$Q$ 和 $K$ 都是上一层的表示 $\mathbf{h}^{(l-1)}$。用这些 $\mathbf{\tilde{A}}$ 代替 $\mathbf{A}$ 就可实现“软修剪”了。这个机制的效果如下所示:
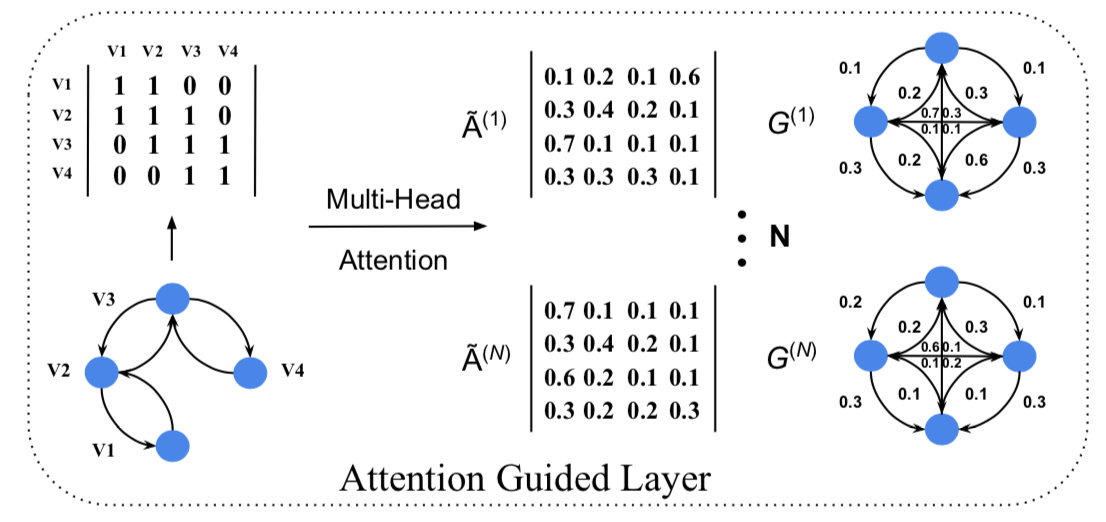
特别地,我们将原始依存树的邻接矩阵作为注意力矩阵的初始值,这样就可以在节点表示中捕获依存信息,以便之后进行 Attention 计算。
本文魔改自《依存句法分析在深度学习中的应用》,原作者:何晗