转载自《简明条件随机场CRF介绍(附带纯Keras实现)》和《CRF用过了,不妨再了解下更快的MEMM?》,作者:苏剑林,部分内容有修改。
HMM、MEMM、CRF 被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM 和 MEMM 似乎都“没落”了,舞台上就只留下 CRF。相信做 NLP 的读者朋友们就算没亲自做过也会听说过 BiLSTM+CRF 做中文分词、命名实体识别等任务,却几乎没有听说过 BiLSTM+HMM、BiLSTM+MEMM 的,这是为什么呢?
softmax 和 CRF
我们首先来对比一下普通的逐帧 softmax 和 CRF 的异同。
逐帧 softmax
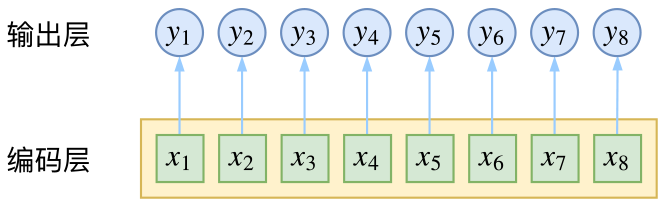
CRF 主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用 CNN 或者 RNN 进行编码后,接一个全连接层用 softmax 激活,如下图所示
条件随机场
然而,当我们设计标签时,比如用 s、b、m、e 的 4 个标签来做字标注法的分词,目标输出序列本身会带有一些上下文关联,比如 s 后面就不能接 m 和 e,等等。逐标签 softmax 并没有考虑这种输出层面的上下文关联,所以它意味着把这些关联放到了编码层面,希望模型能自己学到这些内容,但有时候会“强模型所难”。
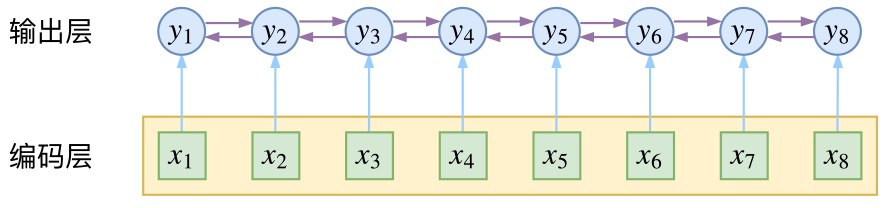
而CRF则更直接一点,它将输出层面的关联分离了出来,这使得模型在学习上更为“从容”:
CRF
当然,如果仅仅是引入输出的关联,还不仅仅是 CRF 的全部,CRF 的真正精巧的地方,是它以路径为单位,考虑的是路径的概率。
模型概要
假如一个输入有 $n$ 帧,每一帧的标签有 $k$ 种可能性,那么理论上就有 $k^n$ 种不同的输出。我们可以将它用如下的网络图进行简单的可视化。在下图中,每个点代表一个标签的可能性,点之间的连线表示标签之间的关联,而每一种标注结果,都对应着图上的一条完整的路径。
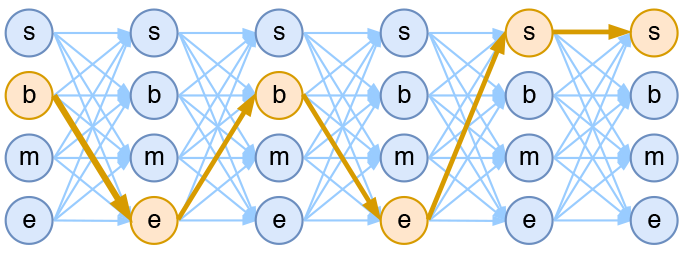
而在序列标注任务中,我们的正确答案是一般是唯一的。比如“今天天气不错”,如果对应的分词结果是“今天/天气/不/错”,那么目标输出序列就是 bebess,除此之外别的路径都不符合要求。换言之,在序列标注任务中,我们的研究的基本单位应该是路径,我们要做的事情,是从 $k^n$ 条路径选出正确的一条,那就意味着,如果将它视为一个分类问题,那么将是 $k^n$ 类中选一类的分类问题!
这就是逐帧 softmax 和 CRF 的根本不同了:前者将序列标注看成是 $n$ 个 $k$ 分类问题,后者将序列标注看成是 $1$ 个 $k^n$ 分类问题。
具体来讲,在 CRF 的序列标注问题中,我们要计算的是条件概率
\[P(y_1,\dots,y_n\mid x_1,\dots,x_n)=P(y_1,\dots,y_n\mid\boldsymbol{x}),\quad \boldsymbol{x}=(x_1,\dots,x_n)\tag{1}\]为了得到这个概率的估计,CRF 做了两个假设:
假设一 该分布是指数族分布。
这个假设意味着存在函数 $f(y_1,\dots,y_n;\boldsymbol{x})$,使得
\[P(y_1,\dots,y_n\mid\boldsymbol{x})=\frac{1}{Z(\boldsymbol{x})}\exp\Big(f(y_1,\dots,y_n;\boldsymbol{x})\Big)\tag{2}\]其中 $Z(\boldsymbol{x})$ 是归一化因子,因为这个是条件分布,所以归一化因子跟有 $\boldsymbol{x}$ 关。这个 $f$ 函数可以视为一个打分函数,打分函数取指数并归一化后就得到概率分布。
假设二 输出之间的关联仅发生在相邻位置,并且关联是指数加性的。
这个假设意味着 $f(y_1,\dots,y_n;\boldsymbol{x})$ 可以更进一步简化为
\[\begin{aligned}f(y_1,\dots,y_n;\boldsymbol{x})=&h(y_1;\boldsymbol{x})+g(y_1,y_2;\boldsymbol{x})+h(y_2;\boldsymbol{x})+g(y_2,y_3;\boldsymbol{x})+h(y_3;\boldsymbol{x})\\ &+\dots+g(y_{n-1},y_n;\boldsymbol{x})+h(y_n;\boldsymbol{x})\end{aligned}\tag{3}\]这也就是说,现在我们只需要对每一个标签和每一个相邻标签对分别打分,然后将所有打分结果求和得到总分。
线性链 CRF
尽管已经做了大量简化,但一般来说,$(3)$ 式所表示的概率模型还是过于复杂,难以求解。于是考虑到当前深度学习模型中,RNN 或者层叠 CNN 等模型已经能够比较充分捕捉各个 $y$ 与输入 $\boldsymbol{x}$ 的联系,因此,我们不妨考虑函数 $g$ 跟 $\boldsymbol{x}$ 无关,那么
\[\begin{aligned}f(y_1,\dots,y_n;\boldsymbol{x})=h(y_1;\boldsymbol{x})+&g(y_1,y_2)+h(y_2;\boldsymbol{x})+\dots\\ +&g(y_{n-1},y_n)+h(y_n;\boldsymbol{x})\end{aligned}\tag{4}\]这时候 $g$ 实际上就是一个有限的、待训练的参数矩阵而已,而单标签的打分函数 $h(y_i;\boldsymbol{x})$ 我们可以通过 RNN 或者 CNN 来建模。因此,该模型是可以建立的,其中概率分布变为
\[P(y_1,\dots,y_n\mid\boldsymbol{x})=\frac{1}{Z(\boldsymbol{x})}\exp\left(h(y_1;\boldsymbol{x})+\sum_{k=1}^{n-1}\Big[g(y_k,y_{k+1})+h(y_{k+1};\boldsymbol{x})\Big]\right)\tag{5}\]这就是线性链 CRF 的概念。
归一化因子
为了训练 CRF 模型,我们用最大似然方法,也就是用
\[-\log P(y_1,\dots,y_n|\boldsymbol{x})\tag{6}\]作为损失函数,可以算出它等于
\[-\left(h(y_1;\boldsymbol{x})+\sum_{k=1}^{n-1}\Big[g(y_k,y_{k+1})+h(y_{k+1};\boldsymbol{x})\Big]\right)+\log Z(\boldsymbol{x})\tag{7}\]其中第一项是原来概率式的分子的对数,它是目标的序列的打分,虽然看上去挺迂回的,但是并不难计算。真正的难度在于分母的对数 $\log Z(\boldsymbol{x})$ 这一项。
归一化因子,在物理上也叫配分函数,在这里它需要我们对所有可能的路径的打分进行指数求和,而我们前面已经说到,这样的路径数是指数量级的($k^n$),因此直接来算几乎是不可能的。
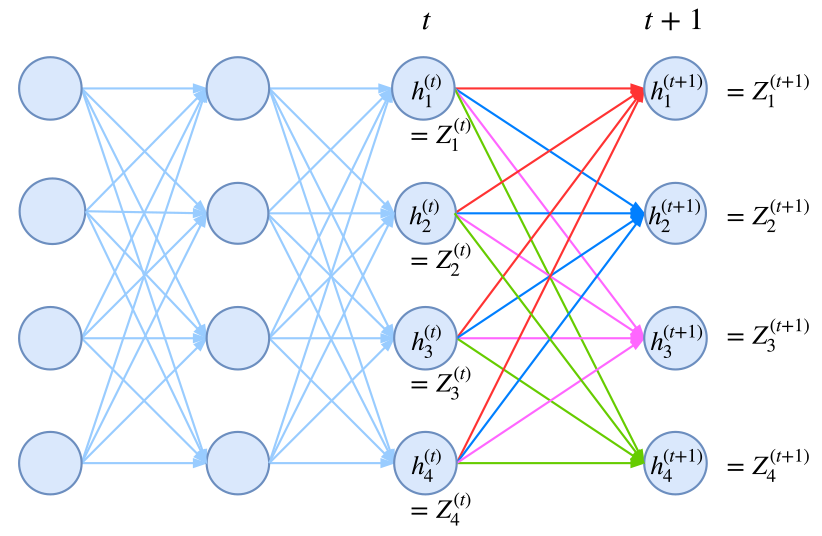
事实上,归一化因子难算,几乎是所有概率图模型的公共难题。幸运的是,在 CRF 模型中,由于我们只考虑了临近标签的联系(马尔可夫假设),因此我们可以递归地算出归一化因子,这使得原来是指数级的计算量降低为线性级别。具体来说,我们将计算到时刻 $t$ 的归一化因子记为 $Z_t$,并将它分为 $k$ 个部分
\[Z_t = Z^{(1)}_t + Z^{(2)}_t + \dots + Z^{(k)}_t\tag{8}\]其中 $Z^{(1)}_t,\dots,Z^{(k)}_t$ 分别是截止到当前时刻 $t$ 中、以标签 $1,\dots,k$ 为终点的所有路径的得分指数和。那么,我们可以递归地计算
\[\begin{aligned}Z^{(1)}_{t+1} = &\Big(Z^{(1)}_t G_{11} + Z^{(2)}_t G_{21} + \dots + Z^{(k)}_t G_{k1} \Big) H_{t+1}(1|\boldsymbol{x})\\ Z^{(2)}_{t+1} = &\Big(Z^{(1)}_t G_{12} + Z^{(2)}_t G_{22} + \dots + Z^{(k)}_t G_{k2} \Big) H_{t+1}(2|\boldsymbol{x})\\ &\qquad\qquad\vdots\\ Z^{(k)}_{t+1} =& \Big(Z^{(1)}_t G_{1k} + Z^{(2)}_t G_{2k} + \dots + Z^{(k)}_t G_{kk} \Big) H_{t+1}(k|\boldsymbol{x}) \end{aligned}\tag{9}\]它可以简单写为矩阵形式
\[\boldsymbol{Z}_{t+1} = \boldsymbol{Z}_{t} \boldsymbol{G}\otimes H(y_{t+1}|\boldsymbol{x})\tag{10}\]其中 $\boldsymbol{Z}_{t}=\Big[Z^{(1)}_t,\dots,Z^{(k)}_t\Big]$;而 $\boldsymbol{G}$ 是对矩阵 $g$ 各个元素取指数后的矩阵(前面已经说过,最简单的情况下,$g$ 只是一个矩阵,代表某个标签到另一个标签的分数),即 $\boldsymbol{G}_{ij}=e^{g_{ij}}$;而 $H(y_{t+1}\mid\boldsymbol{x})$ 是编码模型 $h(y_{t+1}\mid\boldsymbol{x})$(RNN、CNN 等)对位置 $t+1$ 的各个标签的打分的指数,即 $H(y_{t+1}\mid\boldsymbol{x})=e^{h(y_{t+1}\mid\boldsymbol{x})}$,也是一个向量。式 $(10)$ 中,$\boldsymbol{Z}_{t} \boldsymbol{G}$ 这一步是矩阵乘法,得到一个向量,而 $\otimes$ 是两个向量的逐位对应相乘。
动态规划
写出损失函数 $-\log P(y_1,\dots,y_n\mid\boldsymbol{x})$ 后,就可以完成模型的训练了,因为目前的深度学习框架都已经带有自动求导的功能,只要我们能写出可导的 loss,就可以帮我们完成优化过程了。
那么剩下的最后一步,就是模型训练完成后,如何根据输入找出最优路径来。跟前面一样,这也是一个从 $k^n$ 条路径中选最优的问题,而同样地,因为马尔可夫假设的存在,它可以转化为一个动态规划问题,用 viterbi 算法解决,计算量正比于 $n$。
CRF 实现
经过调试,基于 Keras 框架下,笔者得到了一个线性链 CRF 的简明实现,这也许是最简短的 CRF 实现了。这里分享最终的实现并介绍实现要点。
前面我们已经说明了,实现 CRF 的困难之处是 $-\log P(y_1,\dots,y_n\mid\boldsymbol{x})$ 的计算,而本质困难是归一化因子部分 $Z(\boldsymbol{x})$ 的计算,得益于马尔科夫假设,我们得到了递归的 $(9)$ 式或 $(10)$ 式,它们应该已经是一般情况下计算 $Z(\boldsymbol{x})$ 的计算了。
那么怎么在深度学习框架中实现这种递归计算呢?要注意,从计算图的视角看,这是通过递归的方法定义一个图,而且这个图的长度还不固定。这对于 pytorch 这样的动态图框架应该是不为难的,但是对于 tensorflow 或者 Keras 就很难操作了(它们是静态图框架)。不过可以用封装好的 rnn 函数来计算!我们知道,rnn 本质上就是在递归计算
\[\boldsymbol{h}_{t+1} = f(\boldsymbol{x}_{t+1}, \boldsymbol{h}_{t})\]新版本的 tensorflow 和 Keras 都已经允许我们自定义 rnn 细胞,这就意味着函数 $f$ 可以自行定义,而后端自动帮我们完成递归计算。于是我们只需要设计一个 rnn,使得我们要计算的 $\boldsymbol{Z}$ 对应于 rnn 的隐藏向量!
from keras.layers import Layer
import keras.backend as K
class CRF(Layer):
"""纯Keras实现CRF层
CRF层本质上是一个带训练参数的loss计算层,因此CRF层只用来训练模型,
而预测则需要另外建立模型。
"""
def __init__(self, ignore_last_label=False, **kwargs):
"""ignore_last_label:定义要不要忽略最后一个标签,起到mask的效果
"""
self.ignore_last_label = 1 if ignore_last_label else 0
super(CRF, self).__init__(**kwargs)
def build(self, input_shape):
self.num_labels = input_shape[-1] - self.ignore_last_label
self.trans = self.add_weight(name='crf_trans',
shape=(self.num_labels, self.num_labels),
initializer='glorot_uniform',
trainable=True)
def log_norm_step(self, inputs, states):
"""递归计算归一化因子
要点:1、递归计算;2、用logsumexp避免溢出。
技巧:通过expand_dims来对齐张量。
"""
inputs, mask = inputs[:, :-1], inputs[:, -1:]
states = K.expand_dims(states[0], 2) # (batch_size, output_dim, 1)
trans = K.expand_dims(self.trans, 0) # (1, output_dim, output_dim)
outputs = K.logsumexp(states + trans, 1) # (batch_size, output_dim)
outputs = outputs + inputs
outputs = mask * outputs + (1 - mask) * states[:, :, 0]
return outputs, [outputs]
def path_score(self, inputs, labels):
"""计算目标路径的相对概率(还没有归一化)
要点:逐标签得分,加上转移概率得分。
技巧:用“预测”点乘“目标”的方法抽取出目标路径的得分。
"""
point_score = K.sum(K.sum(inputs * labels, 2), 1, keepdims=True) # 逐标签得分
labels1 = K.expand_dims(labels[:, :-1], 3)
labels2 = K.expand_dims(labels[:, 1:], 2)
labels = labels1 * labels2 # 两个错位labels,负责从转移矩阵中抽取目标转移得分
trans = K.expand_dims(K.expand_dims(self.trans, 0), 0)
trans_score = K.sum(K.sum(trans * labels, [2, 3]), 1, keepdims=True)
return point_score + trans_score # 两部分得分之和
def call(self, inputs): # CRF本身不改变输出,它只是一个loss
return inputs
def loss(self, y_true, y_pred): # 目标y_pred需要是one hot形式
if self.ignore_last_label:
mask = 1 - y_true[:, :, -1:]
else:
mask = K.ones_like(y_pred[:, :, :1])
y_true, y_pred = y_true[:, :, :self.num_labels], y_pred[:, :, :self.num_labels]
path_score = self.path_score(y_pred, y_true) # 计算分子(对数)
init_states = [y_pred[:, 0]] # 初始状态
y_pred = K.concatenate([y_pred, mask])
log_norm, _, _ = K.rnn(self.log_norm_step, y_pred[:, 1:], init_states) # 计算Z向量(对数)
log_norm = K.logsumexp(log_norm, 1, keepdims=True) # 计算Z(对数)
return log_norm - path_score # 即log(分子/分母)
def accuracy(self, y_true, y_pred): # 训练过程中显示逐帧准确率的函数,排除了mask的影响
mask = 1 - y_true[:, :, -1] if self.ignore_last_label else None
y_true, y_pred = y_true[:, :, :self.num_labels], y_pred[:, :, :self.num_labels]
isequal = K.equal(K.argmax(y_true, 2), K.argmax(y_pred, 2))
isequal = K.cast(isequal, 'float32')
if mask == None:
return K.mean(isequal)
else:
return K.sum(isequal * mask) / K.sum(mask)
使用案例
我的 Github 中还附带了一个使用 CNN+CRF 实现的中文分词的例子,用的是 Bakeoff 2005 语料,例子是一个完整的分词实现,包括 viterbi 算法、分词输出等。
Github地址:https://github.com/bojone/crf/
MEMM
MEMM 全称 Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退 80% 的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是 MEMM 还是 CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
简单起见,本文介绍的 CRF 和 MEMM 都是最简单的“线性链”版本。
回顾 CRF
本文都是以序列标注为例,即输入序列 $\boldsymbol{x}=(x_1,x_2,\dots,x_n)$,希望输出同样长度的标签序列 $\boldsymbol{y}=(y_1,y_2,\dots,y_n)$,那么建模的就是概率分布
\[P(\boldsymbol{y}\mid\boldsymbol{x})=P(y_1,y_2,\dots,y_n\mid\boldsymbol{x})\tag{11}\]CRF 把 $\boldsymbol{y}$ 看成一个整体,算一个总得分,计算公式如下
\[\begin{aligned}f(y_1,y_2,\dots,y_n;\boldsymbol{x})=&\,f(y_1;\boldsymbol{x})+g(y_1,y_2)+\dots+g(y_{n-1},y_n)+f(y_n;\boldsymbol{x})\\ =&\,f(y_1;\boldsymbol{x}) + \sum_{k=2}^n \big(g(y_{k-1},y_k)+f(y_k;\boldsymbol{x})\big)\end{aligned} \tag{12}\]这个打分函数的特点就是显式地考虑了相邻标签的关联,其实 $g(y_{k-1},y_k)$ 被称为转移矩阵。现在得分算出来了,概率就是得分的 softmax,所以最终概率分布的形式设为
\[P(\boldsymbol{y}\mid\boldsymbol{x})=\frac{e^{f(y_1,y_2,\dots,y_n;\boldsymbol{x})}}{\sum\limits_{y_1,y_2,\dots,y_n}e^{f(y_1,y_2,\dots,y_n;\boldsymbol{x})}} \tag{13}\]总的来说,CRF 就是将目标序列当成一个整体,先给目标设计一个打分函数,然后对打分函数进行整体的 softmax,这个建模理念跟普通的分类问题是一致的。CRF 的困难之处在于代码实现,因为上式的分母项包含了所有路径的求和,这并不是一件容易的事情,但在概念理解上,并没有什么特别困难之处。
更朴素的 MEMM
MEMM,它可以看成一个极度简化的 seq2seq 模型。对于目标 $(11)$,它考虑分解
\[\begin{aligned}P(y_1,y_2,\dots,y_n\mid\boldsymbol{x})&= P(y_1\mid\boldsymbol{x})P(y_2\mid\boldsymbol{x},y_1)P(y_3\mid\boldsymbol{x},y_1,y_2)\\&\quad\dots P(y_n\mid\boldsymbol{x},y_1,y_2,\dots,y_{n-1}) \end{aligned} \tag{14}\]然后假设标签的依赖只发生在相邻位置,所以
\[P(y_1,y_2,\dots,y_n\mid\boldsymbol{x})=P(y_1\mid\boldsymbol{x})P(y_2\mid\boldsymbol{x},y_1)P(y_3\mid\boldsymbol{x},y_2)\dots P(y_n\mid\boldsymbol{x},y_{n-1}) \tag{15}\]接着仿照线性链 CRF 的设计,我们可以设
\[P(y_1\mid\boldsymbol{x})=\frac{e^{f(y_1;\boldsymbol{x})}}{\sum\limits_{y_1}e^{f(y_k;\boldsymbol{x})}},\quad P(y_k\mid\boldsymbol{x},y_{k-1})=\frac{e^{g(y_{k-1},y_k)+f(y_k;\boldsymbol{x})}}{\sum\limits_{y_k}e^{g(y_{k-1},y_k)+f(y_k;\boldsymbol{x})}} \tag{16}\]至此,这就得到了 MEMM 了。由于 MEMM 已经将整体的概率分布分解为逐步的分布之积了,所以算 loss 只需要把每一步的交叉熵求和。
将式 $(16)$ 代回式 $(15)$,我们可以得到
\[P(\boldsymbol{y}\mid\boldsymbol{x})=\frac{e^{f(y_1;\boldsymbol{x})+g(y_1,y_2)+\dots+g(y_{n-1},y_n)+f(y_n;\boldsymbol{x})}}{\left(\sum\limits_{y_1}e^{f(y_1;\boldsymbol{x})}\right)\left(\sum\limits_{y_2}e^{g(y_1,y_2)+f(y_2;\boldsymbol{x})}\right)\dots\left(\sum\limits_{y_n}e^{g(y_{n-1},y_n)+f(y_n;\boldsymbol{x})}\right)} \tag{17}\]对比式 $(17)$ 和式 $(13)$,我们可以发现,MEMM 跟 CRF 的区别仅在于分母(也就是归一化因子)的计算方式不同,CRF 的式 $(13)$ 我们称之为是全局归一化的,而 MEMM 的式 $(17)$ 我们称之为是局部归一化的。
MEMM 的优劣
MEMM 的一个明显的特点是实现简单、速度快,因为它只需要每一步单独执行 softmax,所以 MEMM 是完全可以并行的,速度跟直接逐步 Softmax 基本一样。而对于 CRF,式 $(13)$ 的分母并不是那么容易算的,它最终转化为一个递归计算,可以在 $\mathscr{O}(n)$ 的时间内算出来,递归就意味着是串行的,因此当我们模型的主体部分是高度可并行的架构(比如纯 CNN 或纯 Attention 架构)时,CRF 会严重拖慢模型的训练速度。后面我们有比较 MEMM 和 CRF 的训练速度(当然,仅仅是训练慢了,预测阶段 MEMM 和 CRF 的速度都一样)。
至于劣势,自然也是有的。前面我们提到过,MEMM 可以看成是一个极度简化的 seq2seq 模型。既然是这样,那么普通 seq2seq 模型有的弊端它都有。seq2seq 中有一个明显的问题是 exposure bias,对应到 MEMM 中,它被称之为 label bias,大概意思是:在训练 MEMM 的时候,对于当前步的预测,都是假设前一步的真实标签已知,这样一来,如果某个标签 $A$ 后面只能接标签 $B$,那么模型只需要通过优化转移矩阵就可以实现这一点,而不需要优化输入 $\boldsymbol{x}$ 对 $B$ 的影响(即没有优化好 $f(B;\boldsymbol{x})$);然而,在预测阶段,真实标签是不知道的,我们可能无法以较高的置信度预测前一步的标签 $A$,而由于在训练阶段,当前步的 $f(B;\boldsymbol{x})$ 也没有得到强化,所以当前步 $B$ 也无法准确预测,这就有可能导致错误的预测结果。
双向 MEMM
label bias 可能不好理解,但我们可以从另外一个视角看 MEMM 的不足:事实上,相比 CRF,MEMM 明显的一个不够漂亮的地方就是它的不对称性——它是从左往右进行概率分解的。笔者的实验表明,如果能解决这个不对称性,能够稍微提高 MEMM 的效果。笔者的思路是:将 MEMM 也从右往左做一遍,这时候对应的概率分布是
\[P(\boldsymbol{y}\mid\boldsymbol{x})=\frac{e^{f(y_1;\boldsymbol{x})+g(y_1,y_2)+\dots+g(y_{n-1},y_n)+f(y_n;\boldsymbol{x})}}{\left(\sum\limits_{y_n}e^{f(y_n;\boldsymbol{x})}\right)\left(\sum\limits_{y_{n-1}}e^{g(y_n,y_{n-1})+f(y_{n-1};\boldsymbol{x})}\right)\dots\left(\sum\limits_{y_1}e^{g(y_2,y_1)+f(y_1;\boldsymbol{x})}\right)} \tag{18}\]然后也算一个交叉熵,跟从左往右的式 $(17)$ 的交叉熵平均,作为最终的 loss。这样一来,模型同时考虑了从左往右和从右往左两个方向,并且也不用增加参数,弥补了不对称性的缺陷。作为区分,笔者类比 Bi-LSTM 的命名,将其称为 Bi-MEMM。
论文《Bidirectional Inference with the Easiest-First Strategy for Tagging Sequence Data》首次提出 Bi-MEMM 这个概念,里边的 Bi-MEMM 是指一种 MEMM 的双向解码策略,跟本文的 Bi-MEMM 含义并不相同。
实验结果演示
为了验证和比较 MEMM 的效果,笔者将 CRF 和 MEMM 同时写进了 bert4keras 中,并且写了中文分词(task_sequence_labeling_cws_crf.py)和中文命名实体识别(task_sequence_labeling_ner_crf.py)两个脚本。在这两个脚本中,从 CRF 切换到 MEMM 非常简单,只需将 ConditionalRandomField 替换为 MaximumEntropyMarkovModel。
下面直接给出一些相对比较的结果:
- 相同的实验参数下,Bi-MEMM 总是优于 MEMM,MEMM 总是优于 Softmax;
- 相同的实验参数下,CRF 基本上不差于 Bi-MEMM;
- 当编码模型能力比较强时,CRF 与 Bi-MEMM 效果持平;当编码模型较弱时,CRF 优于 Bi-MEMM,幅度约为 0.5% 左右;
- 用 12 层 bert base 模型作为编码模型时,Bi-MEMM 比 CRF 快 25%;用 2 层 bert base 模型作为编码模型时,Bi-MEMM 比 CRF 快 1.5 倍。
注:由于发现 Bi-MEMM 效果总比 MEMM 略好,并且两者的训练时间基本无异,所以 bert4keras 里边的 MaximumEntropyMarkovModel 默认就是 Bi-MEMM。
思考与拓展
根据上面的结论,在深度学习时代,MEMM 的“没落”似乎就可以理解了——MEMM 除了训练速度快点之外,相比 CRF 似乎也就没什么好处了,两者的预测速度是一样的,而很多时候我们主要关心预测速度和效果,训练速度稍微慢点也无妨。这两个模型的比较结果是有代表性的,可以说这正是所有全局归一化和局部归一化模型的差异:全局归一化模型效果通常好些,但实现通常相对困难一些;局部归一化模型效果通常不超过全局归一化模型,但胜在易于实现,并与易于拓展。
如何易于拓展?这里举两个方向的例子。
第一个例子,假如标签数很大的时候,比如用序列标注的方式做文本纠错或者文本生成时(相关例子可以参考论文《Fast Structured Decoding for Sequence Models》),标签的数目就是词表里边的词汇数 $\vert V\vert$,就算用了 subword 方法,词汇数少说也有一两万,这时候转移矩阵的参数量就达到数亿($\vert V\vert^2$),难以训练。读者可能会想到低秩分解,不错,低秩分解可以将转移矩阵的参数量控制为 $2d\vert V\vert$,其中 $d$ 是分解的中间层维度。不幸的是,对于 CRF 来说,低秩分解不能改变归一化因子计算量大的事实,因为 CRF 的归一化因子依然需要恢复为 $\vert V\vert\times\vert V\vert$ 的转移矩阵才能计算下去,所以对于标签数目巨大的场景,CRF 无法直接使用。但幸运的是,对于 MEMM 来说,低秩分解可以有效低降低训练时的计算量,从而依然能够有效的使用。bert4keras 里边所带的MaximumEntropyMarkovModel 已经把低秩序分解集成进去了,有兴趣的读者可以查看源码了解细节。
第二个例子,上述介绍的 CRF 和 MEMM 都只考虑相邻标签之间的关联,如果我要考虑更复杂的邻接关联呢?比如同时考虑 $y_k$ 跟 $y_{k-1},y_{k-2}$ 的关联?这时候 CRF 的全局归一化思路就很难操作了,归根结底还是归一化因子难算;但如果是 MEMM 的局部归一化思路就容易进行。
转载自《简明条件随机场CRF介绍(附带纯Keras实现)》和《CRF用过了,不妨再了解下更快的MEMM?》,作者:苏剑林,部分内容有修改。