本文内容摘取自 《Deep Learning》,部分内容有修改。
超参数和验证集
大多数机器学习算法都有超参数来控制算法行为,超参数的值不是通过学习算法本身学习出来的。有时一个选项被设为超参数是因为它太难优化了,更多的情况是该选项不适合在训练集上学习。例如在训练集上学习控制模型容量的超参数,这些超参数总是趋向于最大可能的模型容量,导致过拟合。
为了解决这个问题,我们需要一个训练算法观测不到的验证集 (validation set) 样本。
早先我们讨论过和训练数据相同分布的样本组成的测试集用来估计学习器的泛化误差,其重点在于测试样本不能以任何形式参与到模型的选择中 (包括设定超参数)。基于这个原因,测试集中的样本不能用于验证集,因此我们总是从训练数据中构建验证集。
我们将训练数据成两个不相交的子集,一个用于学习参数,另一个作为验证集,用于估计泛化误差,更新超参数。用于学习参数的数据子集通常仍被称为训练集,用于挑选超参数的数据子集被称为验证集 (validation set)。通常 80% 的训练数据用于训练,20% 用于验证。
交叉验证
当数据集有十万计或者更多的样本时不会有什么问题,但是如果我们只有一个小规模的测试集则意味着对于平均测试误差估计的统计具有不确定性 (在小的测试集上,损失函数可能具有过高的方差),使得很难判断算法 A 是否比算法 B 在给定的任务上做得更好。
一种替代方法就是使用所有的样本来估计平均测试误差,最常见的是 $k$-折交叉验证,将数据集分成 $k$ 个不重合的子集,测试误差可以估计为 $k$ 次计算后的平均测试误差。在第 $i$ 次测试时,数据的第 $i$ 个子集用作测试集,其他的数据用作训练集。其算法如下:
对于给定数据集 $\mathbb{D}$,其中元素为样本 $\boldsymbol{z}^{(i)}$,$k$-折交叉验证算法用于估计学习算法 $A$ 的泛化误差。单个样本上的误差可用于计算平均值周围的置信区间,如式 (5.47) 所示。虽然这些置信区间在使用交叉验证之后不能很好地证明,但是通常的做法是只有当算法 $A$ 误差的置信区间低于并且不与算法 $B$ 的置信区间相交时,我们才声明算法 $A$ 比算法 $B$ 更好。
将 $\mathbb{D}$ 分为 $k$ 个互斥子集 $\mathbb{D}_i$,它们的并集为 $\mathbb{D}$
\[\begin{align} &\textbf{for } i \textbf{ from } 1 \text{ to } k \textbf{ do} \\ &\quad f_i = A(\mathbb{D}\backslash\mathbb{D}_i)\\ &\quad \textbf{for } \boldsymbol{z}^{(j)} \text{ in } \mathbb{D}_i \textbf{ do}\\ & \quad \quad e_j = L(f_i,\boldsymbol{z}^{(j)})\\ & \quad \textbf{end for}\\ & \textbf{end for}\\ & \textbf{Return } \boldsymbol{e} \end{align}\]其中,$A$ 为学习算法 (使用数据集作为输入,输出一个学好的函数),$L$ 为损失函数,$k$ 为折数。
估计
点估计
点估计试图为一些感兴趣的量提供单个‘‘最优’’ 预测。一般地,感兴趣的量可以是单个参数,或是某些参数模型中的一个向量参数,例如线性回归中的权重,也有可能是整个函数。为了区分参数的估计值和真实值,我们习惯将参数 $\boldsymbol{\theta}$ 的点估计表示为 $\hat{\boldsymbol{\theta}}$。
令 ${\boldsymbol{x}^{(1)}, . . . , \boldsymbol{x}^{(m)}}$ 是 $m$ 个独立同分布的数据点。点估计 (point estimator) 或 统计量 (statistics) 是这些数据的任意函数:
\[\hat{\boldsymbol{\theta}}_m = g(\boldsymbol{x}^{(1)},...,\boldsymbol{x}^{(m)})\]点估计的定义非常宽泛,不要求 $g$ 返回一个接近真实 $\boldsymbol{\theta}$ 的值,也不要求 $g$ 的值域在 $\boldsymbol{\theta}$ 的允许取值范围内。我们采取频率派在统计上的观点,假设真实参数 $\boldsymbol{\theta}$ 是固定但未知的,而点估计 $\hat{\boldsymbol{\theta}}$ 是数据的函数。由于数据是随机过程采样出来的,数据的任何函数都是随机的,因此 $\hat{\boldsymbol{\theta}}$ 是一个随机变量。
函数估计
点估计也可以指输入和目标变量之间关系的估计,我们称之为函数估计。这时我们试图从输入向量 $\boldsymbol{x}$ 预测变量 $\boldsymbol{y}$。假设有一个函数 $f(\boldsymbol{x})$ 表示 $\boldsymbol{y}$ 和 $\boldsymbol{x}$ 之间的近似关系,例如假设 $\boldsymbol{y} = f(\boldsymbol{x}) + \boldsymbol{\epsilon}$,其中 $\boldsymbol{\epsilon}$ 是 $\boldsymbol{y}$ 中未能从 $\boldsymbol{x}$ 预测的一部分。在函数估计中,我们感兴趣的是用模型估计去近似 $f$,或者估计 $\hat{f}$。函数估计和估计参数 $\boldsymbol{\theta}$ 是一样的,函数估计 $\hat{f}$ 是函数空间中的一个点估计。
例如线性回归,既可以被解释为估计参数 $\boldsymbol{w}$,又可以被解释为估计从 $\boldsymbol{x}$ 到 $y$ 的函数映射 $\hat{f}$。
偏差
估计的偏差被定义为:
\[\text{bias}(\hat{\boldsymbol{\theta}}_m) = \mathbb{E}(\hat{\boldsymbol{\theta}}_m) − \boldsymbol{\theta} \tag{2.1}\]其中期望作用在所有数据 (看作是从随机变量采样得到的) 上,$\boldsymbol{\theta}$ 是用于定义数据生成分布的 $\boldsymbol{\theta}$ 的真实值。
- 如果 $\text{bias}(\hat{\boldsymbol{\theta}}_m) = 0$,那么估计量 $\hat{\boldsymbol{\theta}}_m$ 被称为是无偏 (unbiased),这意味着 $\mathbb{E}(\hat{\boldsymbol{\theta}}_m) = \boldsymbol{\theta}$。
- 如果 $\lim_{m\rightarrow\infty} \text{bias}(\hat{\boldsymbol{\theta}}_m) = 0$,那么估计量 $\hat{\boldsymbol{\theta}}_m$ 被称为是渐近无偏 (asymptotically unbiased),这意味着 $\lim_{m\rightarrow\infty} \mathbb{E}(\hat{\boldsymbol{\theta}}_m) = \boldsymbol{\theta}$。
示例:伯努利分布
考虑一组服从均值为 $\theta$ 的伯努利分布的独立同分布的样本 ${x^{(1)}, . . . , x^{(m)}}$:
\[P(x^{(i)};θ) = θ^{x^{(i)}}(1−θ)^{(1−x^{(i)})} \tag{2.2}\]分布中参数 $\theta$ 的常用估计量是训练样本的均值:
\[\hat{\theta}_m = \frac{1}{m} \sum_{i=1}^m x^{(i)} \tag{2.3}\]判断这个估计量是否有偏,我们将式 $(2.3)$ 带入式 $(2.1)$:
\[\begin{align} \text{bias}(\hat{\theta}_m) &= \mathbb{E} [\hat{\theta}_m] − \theta \\ &= \mathbb{E}\Bigg[\frac{1}{m}\sum_{i=1}^m x^{(i)}\Bigg]−θ\\ &= \frac{1}{m}\sum_{i=1}^m \mathbb{E}[x^{(i)}]-\theta\\ &= \frac{1}{m}\sum_{i=1}^m\sum_{x^{(i)}=0}^m \Big(x^{(i)}\theta^{x^{(i)}}(1-\theta)^{(1-x^{(i)})}\Big)-\theta\\ &= \frac{1}{m}\sum_{i=1}^m (\theta) - \theta\\ &= \theta - \theta = 0 \end{align}\]因为 $\text{bias}(\hat{\theta}) = 0$,我们称估计 $\hat{\theta}$ 是无偏的。
示例:均值的高斯分布估计
考虑一组独立同分布的样本 ${x^{(1)},… , x^{(m)}}$ 服从高斯分布 $p(x^{(i)}) = \mathcal{N} (x^{(i)}; \mu, \sigma^2)$,其中 $i \in {1, . . . , m}$。高斯均值参数的常用估计量被称为样本均值 (sample mean):
\[\hat{\mu}_m = \frac{1}{m}\sum_{i=1}^m x^{(i)}\]计算它的期望:
\[\begin{align} \text{bias}(\hat{\mu}_m) &= \mathbb{E}[\hat{\mu}_m] - \mu \\ & = \mathbb{E}\Bigg[\frac{1}{m}\sum_{i=1}^m x^{(i)}\Bigg] - \mu \\ &= \Bigg(\frac{1}{m}\sum_{i=1}^m \mathbb{E}[x^{(i)}]\Bigg) - \mu\\ &= \Bigg(\frac{1}{m}\sum_{i=1}^m\mu\Bigg) - \mu\\ &= \mu - \mu = 0 \end{align}\]因此样本均值是高斯均值参数的无偏估计量。
无偏估计虽然令人满意的,但它并不总是“最好”的估计,我们经常会使用其他具有重要性质的有偏估计。
方差和标准差
我们有时还会考虑估计量的期望的变化程度是多少,这可以通过计算它的方差来获得。估计量的方差 (variance) 就是一个方差:
\[\text{Var}(\hat{\theta})\]其中随机变量是训练集。另外,方差的平方根被称为标准差 (standard error),记作 $\text{SE}(\hat{\theta})$。估计量的方差或标准差告诉我们,当独立地从潜在的数据生成过程中重采样数据集时,如何期望估计量的变化。正如我们希望估计的偏差较小,我们也希望其方差较小。
数学概念回顾
高斯分布的样本方差 (sample variance) 为:
\[\hat{\sigma}_m^2 = \frac{1}{m}\sum_{i=1}^m (x^{(i)}-\hat{\mu}_m)^2\]其中 $\hat{\mu}_m=\frac{1}{m}\sum_{i=1}^m x^{(i)}$ 是样本均值。样本方差是有偏估计,它的偏差为 $-\sigma^2/m$:
\[\begin{align} \text{bias}(\hat{\sigma}_m^2) &= \mathbb{E}[\hat{\sigma}_m^2] - \sigma^2\\ &= \mathbb{E}\Bigg[\frac{1}{m}\sum_{i=1}^m(x^{(i)}-\hat{\mu}_m)^2\Bigg] - \sigma^2\\ &=\frac{m-1}{m}\sigma^2 - \sigma^2 = -\frac{\sigma^2}{m} \end{align}\]无偏样本方差 (unbiased sample variance) 为:
\[\tilde{\sigma}_m^2 = \frac{1}{m-1}\sum_{i=1}^m (x^{(i)}-\hat{\mu}_m)^2\]正如名字所言,这个估计是无偏的:
\[\begin{align} \mathbb{E}[\tilde{\sigma}^2_m] &= \mathbb{E}\Bigg[\frac{1}{m-1}\sum_{i=1}^m(x^{(i)}-\hat{\mu_m})^2\Bigg] \\ & = \frac{m}{m-1}\mathbb{E}[\hat{\sigma}^2_m] \\ & = \frac{m}{m-1}\Big(\frac{m-1}{m}\sigma^2\Big) = \sigma^2 \end{align}\]
均值的标准差被记作:
\[\text{SE}(\hat{\mu}_m) = \sqrt{\text{Var}\Bigg[\frac{1}{m}\sum_{i=1}^m x^{(i)}\Bigg]} = \frac{\sigma}{\sqrt{m}}\]其中 $\sigma^2$ 是样本 $x^{(i)}$ 的真实方差,标准差通常被记作 $\sigma$。可惜,样本方差的平方根和方差无偏估计的平方根都不是标准差的无偏估计。这两种计算方法都倾向于低估真实的标准差,但仍用于实际中。相较而言,方差无偏估计的平方根较少被低估。对于较大的 $m$,这种近似非常合理。
均值的标准差在机器学习实验中非常有用,我们通常用测试集样本的误差均值来估计泛化误差。测试集中样本的数量决定了这个估计的精确度。中心极限定理告诉我们均值会接近一个高斯分布,我们可以用标准差计算出真实期望落在选定区间的概率。例如,以均值 $\hat{\mu}_m$ 为中心的 95% 置信区间是:
\[(\hat{\mu}_m - 1.96 \text{SE}(\hat{\mu}_m), \hat{\mu}_m + 1.96\text{SE}(\hat{\mu}_m))\]在机器学习实验中,我们通常说算法 A 比算法 B 好,是指算法 A 的误差的 95% 置信区间的上界小于算法 B 的误差的 95% 置信区间的下界。
示例:伯努利分布
我们再次考虑从伯努利分布 ($P(x^{(i)};\theta) = \theta^{x^{(i)}}(1-\theta)^{1-x^{(i)}}$) 中独立同分布采样出来的一组样本 ${x^{(1)},…,x^{(m)}}$。这次我们关注估计 $\hat{\theta}m = \frac{1}{m}\sum{i=1}^m x^{(i)}$ 的方差:
\[\begin{align} \text{Var}(\hat{\theta}_m) &= \text{Var}\Bigg(\frac{1}{m}\sum_{i=1}^m x^{(i)}\Bigg)\\ &=\frac{1}{m^2}\sum_{i=1}^m \text{Var}(x^{(i)}) \\ &= \frac{1}{m^2}\sum_{i=1}^m \theta(1-\theta) \\ &= \frac{1}{m^2} m \theta(1-\theta)\\ &= \frac{1}{m}\theta(1-\theta) \end{align}\]估计量方差的下降速率是关于数据集样本数目 $m$ 的函数,这是常见估计量的普遍性质,在探讨一致性时,我们会继续讨论。
权衡偏差和方差以最小化均方误差
偏差和方差度量着估计量的两个不同误差来源。
- 偏差度量着偏离真实函数或参数的误差期望。
- 方差度量着数据上任意特定采样可能导致的估计期望的偏差。
当我们可以在一个偏差更大的估计和一个方差更大的估计中进行选择时,我们该如何选择?
判断这种权衡最常用的方法是交叉验证。经验上,交叉验证在真实世界的许多任务中都非常成功。另外,我们也可以比较这些估计的均方误差 (mean squared error, MSE):
\[\begin{align} \text{MSE} &= \mathbb{E}[(\hat{\theta}_m - \theta)^2]\\ &=\text{Bias}(\hat{\theta}_m)^2 + \text{Var}(\hat{\theta}_m) \end{align}\]MSE 度量着估计和真实参数 $\theta$ 之间平方误差的总体期望偏差,它包含了偏差和方差,理想的估计具有较小的 MSE。
偏差和方差的关系和机器学习容量、欠拟合和过拟合的概念紧密相联。用 MSE 度量泛化误差时,增加容量会增加方差,降低偏差。如下图所示,我们再次在关于容量的函数中,看到泛化误差的 U 形曲线。
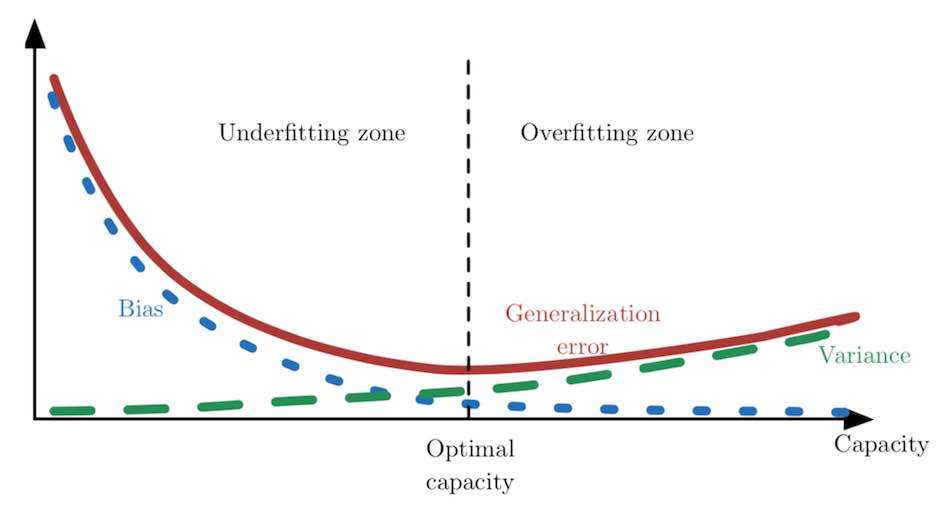
当容量增大时,偏差随之减小,而方差随之增大,使得泛化误差产生了另一种 U 形。
本文内容摘取自 《Deep Learning》,部分内容有修改。