常用概率分布
许多简单的概率分布在机器学习的众多领域中都是有用的。
Bernoulli 分布
Bernoulli 分布 (Bernoulli distribution) 是单个二值随机变量的分布。它由单个参数 $\phi ∈ [0, 1]$ 控制,$\phi$ 给出了随机变量等于 $1$ 的概率。它具有如下的一些性质: \(P(\mathbb{x} = 1) = \phi\\ P(\mathbb{x} = 0) = 1-\phi\\ P(\mathbb{x} = x) = \phi^x(1-\phi)^{1-x}\\ \mathbb{E}_\mathbb{x}[\mathbb{x}] = \phi\\ \text{Var}_\mathbb{x}(\mathbb{x}) = \phi(1-\phi)\)
高斯分布
实数上最常用的分布就是正态分布 (normal distribution),也称为高斯分布 (Gaussian distribution):
\[\mathcal{N}(x;\mu,\sigma^2) = \sqrt{\frac{1}{2\pi\sigma^2}}\exp\bigg(-\frac{1}{2\sigma^2}(x-\mu)^2\bigg)\]下图画出了正态分布的概率密度函数。
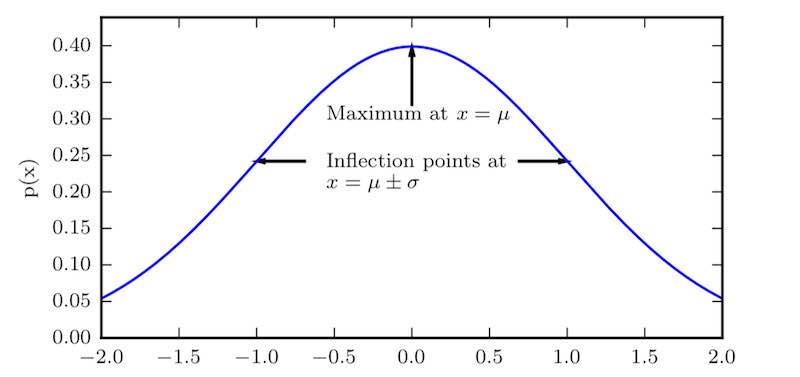
正态分布 $\mathcal{N}(x;\mu,\sigma^2)$ 呈现经典的“钟形曲线”的形状,其中中心峰的 $x$ 坐标由 $\mu$ 给出,峰的宽度受 $\sigma$ 控制。上图中我们展示的是标准正态分布 (standard normal distribution),其中 $\mu = 0,\sigma = 1$。
正态分布由两个参数控制,$\mu \in \mathbb{R}$ 和 $\sigma \in (0,\infty)$。参数 $\mu$ 给出了中心峰值的坐标,这也是分布的均值:$\mathbb{E}[\mathbb{x}] = \mu$。分布的标准差用 $\sigma$ 表示,方差用 $\sigma^2$ 表示。
当我们由于缺乏关于某个实数上分布的先验知识而不知道该选择怎样的形式时,正态分布是默认的比较好的选择,其中有两个原因。
- 我们想要建模的很多分布的真实情况是比较接近正态分布的。中心极限定理 (central limit theorem) 说明很多独立随机变量的和近似服从正态分布。
- 在具有相同方差的所有可能的概率分布中,正态分布在实数上具有最大的不确定性,可以认为正态分布是对模型加入的先验知识量最少的分布。
常用函数的有用性质
某些函数在处理概率分布时经常会出现,尤其是深度学习的模型中用到的概率分布。
其中一个函数是 $\textbf{logistic sigmoid}$ 函数:
\[\sigma(x) = \frac{1}{1 + \exp(-x)} \tag{2.1}\]$\textbf{logistic sigmoid}$ 函数通常用来产生 Bernoulli 分布中的参数 $\phi$,因为它的范围是 $(0, 1)$,处在 $\phi$ 的有效取值范围内。下图给出了 $\text{sigmoid}$ 函数的图示。
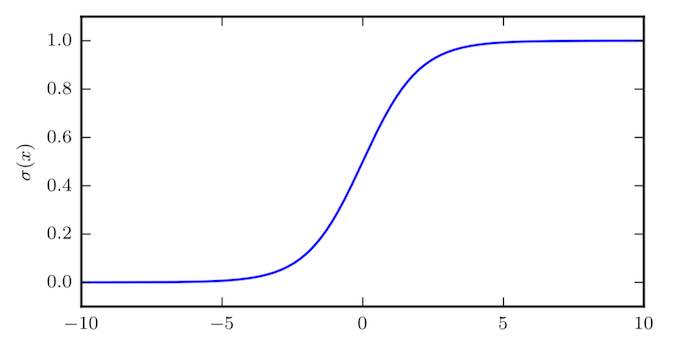
$\text{sigmoid}$ 函数在变量取绝对值非常大的正值或负值时会出现饱和 (saturate) 现象,意味着函数会变得很平,并且对输入的微小改变会变得不敏感。
另外一个经常遇到的函数是 $\textbf{softplus}$ 函数:
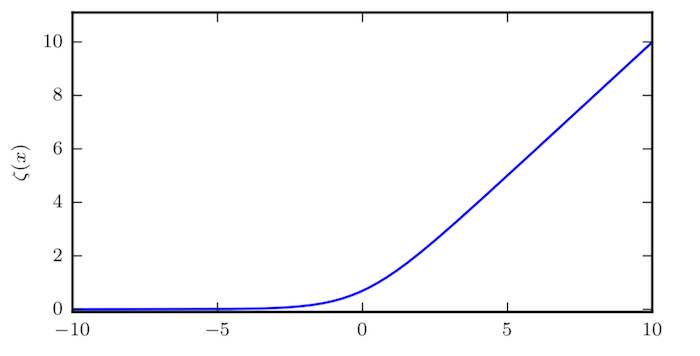
\[\zeta(x) = \log(1+\exp(x)) \tag{2.2}\]$\text{softplus}$ 函数可以用来产生正态分布的 $\sigma$ 参数,因为它的范围是 $(0, \infty)$。$\text{softplus}$ 函数名来源于它是另外一个函数的平滑(或“软化”)形式,这个函数是
\[x^{+} = \max(0,x) \tag{2.3}\]下图给出了 $\text{softplus}$ 函数的图示:
贝叶斯规则
我们经常会需要在已知 $P (\mathbb{y} \mid \mathbb{x})$ 时计算 $P (\mathbb{x} \mid \mathbb{y})$。幸运的是,如果还知道 $P (\mathbb{x})$,我们可以用贝叶斯规则 (Bayes’ rule) 来实现这一目的:
\[P(\mathbb{x}\mid\mathbb{y}) = \frac{P(\mathbb{x})P(\mathbb{y}\mid\mathbb{x})}{P(\mathbb{y})}\]$P(\mathbb{y})$ 通常使用 $P(\mathbb{y}) = \sum_x P(\mathbb{y}\mid x)P(x)$ 来计算,所以我们并不需要事先知道 $P(\mathbb{y})$ 的信息。
信息论
信息论的基本想法是一个不太可能的事件居然发生了,要比一个非常可能的事件发生,能提供更多的信息。消息说:“今天早上太阳升起”信息量是如此之少以至于没有必要发送,但一条消息说:“今天早上有日食”信息量就很丰富。
我们想要通过这种基本想法来量化信息。特别地,
- 非常可能发生的事件信息量要比较少,并且极端情况下,确保能够发生的事件应该没有信息量。
- 较不可能发生的事件具有更高的信息量。
- 独立事件应具有增量的信息。例如,投掷的硬币两次正面朝上传递的信息量,应该是投掷一次硬币正面朝上的信息量的两倍。
为了满足上述三个性质,我们定义一个事件 $\mathbb{x} = x$ 的自信息 (self-information) 为
\[I(x) = - \log P(x) \tag{4.1}\]这里 $\log$ 底数为 $2$,单位是比特 (bit) 或者香农 (shannons)。
当 $\mathbb{x}$ 是连续的,我们使用类似的关于信息的定义,但有些来源于离散形式的性质就丢失了。例如,一个具有单位密度的事件信息量仍然为 $0$,但是不能保证它一定发生。
自信息只处理单个的输出。我们可以用香农熵 (Shannon entropy) 来对整个概率分布中的不确定性总量进行量化:
\[H(\mathbb{x}) = \mathbb{E}_{\mathbb{x}\sim P}[I(x)] = -\mathbb{E}_{\mathbb{x}\sim P}[\log P(x)] \tag{4.2}\]也记作 $H(P)$。换言之,一个分布的香农熵是指遵循这个分布的事件所产生的期望信息总量。它给出了对依据概率分布 $P$ 生成的符号进行编码所需的比特数在平均意义上的下界。那些接近确定性的分布(输出几乎可以确定)具有较低的熵;那些接近均匀分布的概率分布具有较高的熵。当 $x$ 是连续的,香农熵被称为微分熵 (differential entropy)。
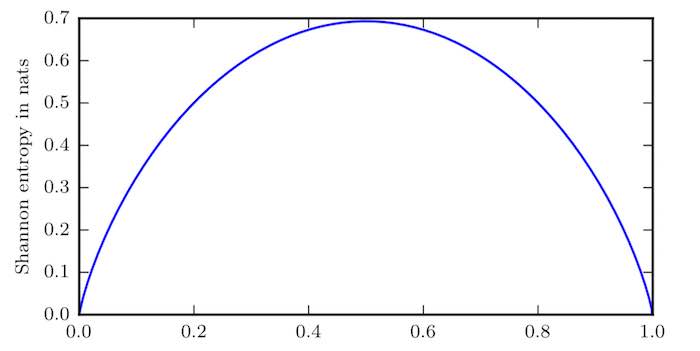
二值随机变量的香农熵
水平轴是 $p$,表示二值随机变量等于 $1$ 的概率。熵由 $(p − 1) \log(1 − p) − p \log p$ 给出,当 $p$ 接近 $0$ 时,分布几乎是确定的,因为随机变量几乎总是 $0$。当 $p$ 接近 $1$ 时,分布也几乎是确定的,因为随机变量几乎总是 $1$。当 $p = 0.5$ 时,熵是最大的, 因为分布在两个结果 ($0$ 和 $1$) 上是均匀的。
如果我们对于同一个随机变量 $\mathbb{x}$ 有两个单独的概率分布 $P(\mathbb{x})$ 和 $Q(\mathbb{x})$,我们可以使用 $\textbf{KL}$ 散度(Kullback-Leibler divergence) 来衡量这两个分布的差异:
\[D_{\text{KL}}(P \parallel Q) = \mathbb{E}_{\mathbb{x}\sim P}\Big[\log \frac{P(x)}{Q(x)}\Big] = \mathbb{E}_{\mathbb{x}\sim P}[\log P(x) - \log Q(x)] \tag{4.3}\]$\text{KL}$ 散度有很多有用的性质,最重要的是它是非负的。$\text{KL}$ 散度为 $0$ 当且仅当 $P$ 和 $Q$ 在离散型变量的情况下是相同的分布,或者在连续型变量的情况下是“几乎处处”相同的。因为 $\text{KL}$ 散度是非负的并且衡量的是两个分布之间的差异,它经常被用作分布之间的某种距离。然而,它并不是真的距离因为它不是对称的:对于某些 $P$ 和 $Q$,$D_{\text{KL}}(P \parallel Q) \ne D_{\text{KL}}(Q \parallel P)$。
一个和 $\text{KL}$ 散度密切联系的量是交叉熵 (cross-entropy) $H(P, Q) = H(P ) + D_{\text{KL}}(P \parallel Q)$,它和 $\text{KL}$ 散度很像但是缺少左边一项:
\[H(P,Q) = -\mathbb{E}_{\mathbb{x}\sim P} \log Q(x) \tag{4.4}\]针对 $Q$ 最小化交叉熵等价于最小化 $\text{KL}$ 散度,因为 $Q$ 并不参与被省略的那一项。
注:在信息论中, $\text{lim}_{x\rightarrow 0} x \log x = 0$。
本文为 《Deep Learning》的学习笔记,感谢 Exacity 小组的翻译。