近年来,随着 BERT、GPT 等大规模预训练语言模型 PLM (Pre-trained Language Models) 的出现,越来越多的 NLP 方法都通过在 PLM 上添加任务相关的结构(任务头)来完成任务。NLP 方法逐渐从“设计模型,从零训练模型”转变为“加载预训练模型,在数据上微调参数”。由于采用无监督/半监督的方式建模语言,PLM 能够在海量数据上进行预训练,从而包含更丰富的语言学知识。
研究表明,PLM 不仅能够学习到文本的语义表示,还包含了语法 (Vig, 2019; Clark et al., 2019)、句法 (Hewitt & Manning, 2019)、常识 (Davison et al., 2019),甚至世界知识 (Petroni et al., 2019; Wang et al., 2020)。
因此,关键问题就变成了——如何有效利用 PLM 中包含的知识来完成下游任务。
以常见的文本分类为例,目前主流的方法是先将文本送入 PLM 中进行编码,然后将输出的语义表示再送入到分类层中完成分类。例如从 BERT 编码结果中取出 $\texttt{[CLS]}$ token 对应的语义表示,然后送入 softmax 激活的单层神经网络中计算每个类别的概率。在训练过程中,可以微调模型中所有的参数(包括 PLM),也可以冻结 PLM,只训练分类层。
近年来,这种“先预训练,再微调”的方式在 NLP 领域获得了巨大的成功,相比过去从零开始训练 BiLSTM、CNN 等模型取得了显著的性能提升。许多研究者认为这种提升正是来源于 PLM 中预先包含的知识。
但是,这种使用方式存在着一个明显的问题:对 PLM 参数的微调过程与其预训练时存在明显差异。例如,大部分 PLM 都通过 Mask Language Model (MLM) 任务进行预训练,其每次随机地遮盖掉句子中的一些词(将这些词替换为 $\texttt{[MASK]}$ token),然后要求模型预测出被遮盖的词。然而,我们在使用 PLM 时,却只通过一些 token 甚至只通过 $\texttt{[CLS]}$ token 来建立 PLM 与最终任务之间的联系。换句话说,我们实际使用 PLM 时只是利用其对文本进行编码,与其预训练时进行的 MLM 等任务完全不同。
那么能不能缩小这种差异呢?答案是肯定的,这就是 Prompt 方法。
1. 什么是 Prompt 方法
Prompt 方法的核心就是通过某个模板将要解决的问题转换到与 PLM 预训练任务类似的形式来进行处理。例如对于文本“I missed the bus today.”,我们可以通过构建模板“I missed the bus today. I felt so $\texttt{[MASK]}$”并使用遮盖语言模型 MLM (Masked Language Model) 预测情绪词来识别它的情感极性,也可以通过构建前缀“English: I missed the bus today. Chinese: $\texttt{[MASK]}$” 然后使用生成模型来获取它对应的中文翻译。
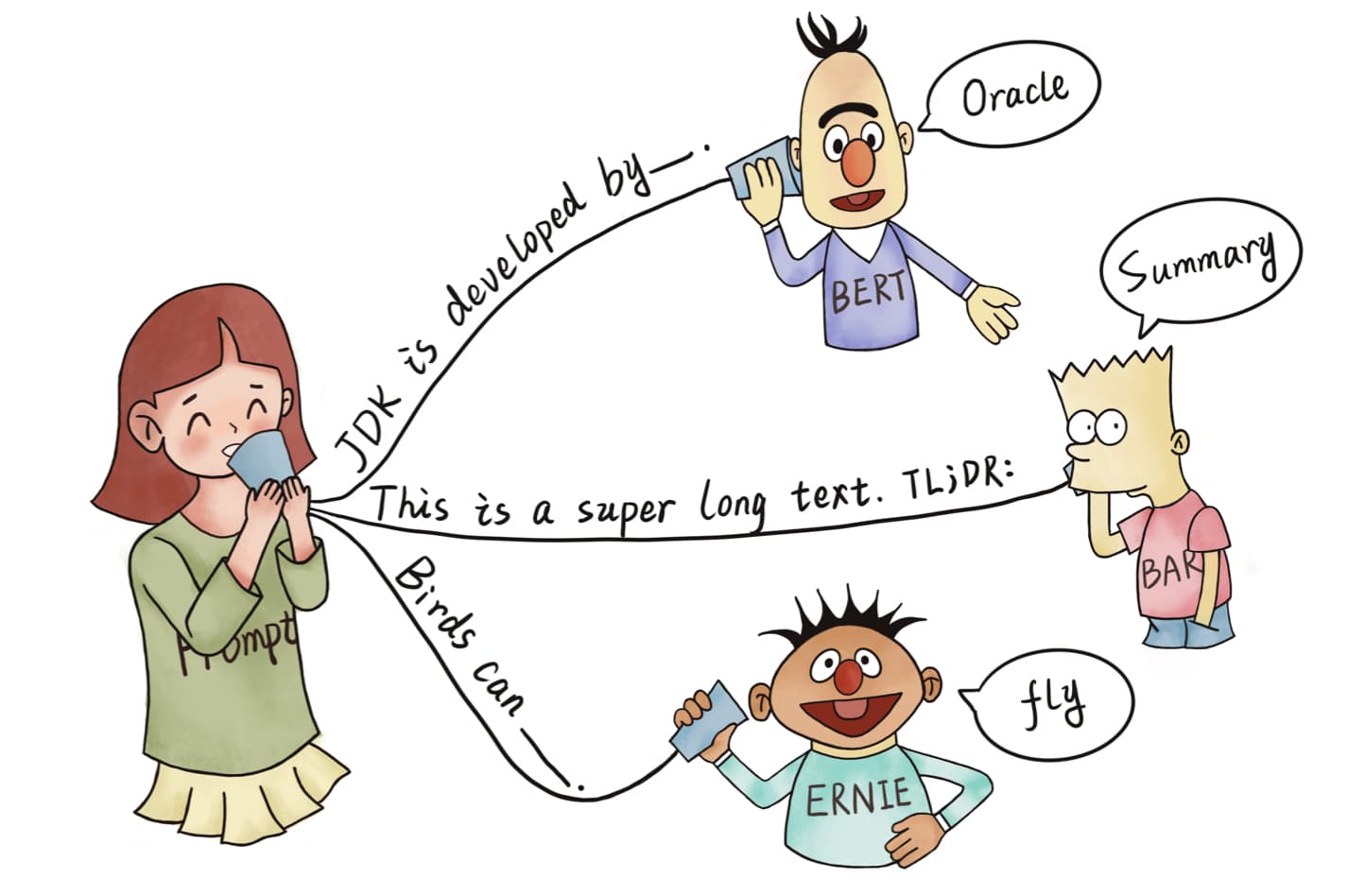
由于这些经过模板转换后的问题在形式上非常接近 PLM 的预训练任务,因此甚至可以在没有任何标注数据(无监督)的情况下完成。
我们把前面这种在模板文本中包含 masked token 的模板称为填充模板 (Cloze Prompt),它会被送入到 MLM 中来预测填充这些槽的 token;把后面这种整个模板文本都在槽之前的模板称为前缀模板 (Prefix Prompt)。通常对于生成类任务或者使用 auto-regressive LM 解决的任务,使用 prefix prompt 会更加合适;对于使用 MLM 解决的任务,cloze prompt 会更加适合,因为它们与预训练任务形式更匹配。
考虑到前缀模板形式比较单一(填充槽固定在末尾),而且大部分 NLP 任务都属于分类问题,下面我们主要介绍 cloze prompt 方法。
1.1 定义
形式上上看,分类问题就是将输入文本 $\textbf{x}\in X$ 映射到一些标签 $y\in Y$,$Y={1,…,k},k\in\mathbb{N}$。我们记预训练 MLM 为 $M$,对应的词表为 $T$,masked token $\texttt{[MASK]} \in T$。Cloze Prompt 共包含两个部分:模板 (Pattern) $P$ 和表意 (Verbalizer) $v$。下图展示了一个对新闻文本 $\textbf{x}$ 进行分类的例子:

- 模板 (Pattern) $P$:将输入映射到一个 cloze 问题,即从输入到 token 序列的映射 $P: X\rightarrow T^*$,并且映射后的 token 序列中会包含特殊的 $\texttt{[MASK]}$ token。例如在上图的例子中模板 $P(\textbf{x}) = \texttt{[MASK]}$ News: $\textbf{x}$;
- 表意 (Verbalizer) $v:Y\rightarrow T$:将每个类别映射到代表其含义的 token。一个合适的表意应该是对于输入 $\textbf{x} \in X$,当且仅当 $y$ 是 $\textbf{x}$ 的正确标签时,$v(y)$ 为模板 $P(\textbf{x})$ 中 $\texttt{[MASK]}$ token 的合适替代。我们把 $v(y)$ 称为类别 $y$ 的表意词 (verbalization),简写为 $v_y$。在上图的例子中,“Sports”就是体育类的表意词。
因此,输入 $X$ 为类别标签 $Y$ 的概率,就是给定对应模板 $P(\textbf{x})$ 中 $\texttt{[MASK]}$ token 为对应表意词 $v_y$ 的概率:
\[q_{\textbf{p}}(y\mid \textbf{x}) = p(\texttt{[MASK]}=v_y\mid P(\textbf{x})) = \frac{\exp M(v_y\mid P(\textbf{x}))}{\sum_{i=1}^k\exp M(v_i\mid P(\textbf{x}))} \tag{1}\]其中 $M(t\mid P(\textbf{x}))$ 表示 MLM 对模板 $P(\textbf{x})$ 中 mask 位置分配 $t$ token 的分数。注意,在预测遮盖词 $\texttt{[MASK]}$ token 的概率时,我们会遮盖掉词表 $T$ 上除表意词之外的其他词,最终计算类别概率只在对应的 $k$ 个表意词上进行,如式 $(1)$ 所示。
这种由模板-表意对 (pattern-verbalizer pairs) 组成的 Prompt 方法最早由 Timo Schick & Hinrich Schütze 在 2020 年的论文《Exploiting cloze questions for few shot text classification and natural language inference》提出,是 PET (Pattern-Exploiting Training) 的重要组成部分。
1.2 常见例子
实际应用中,模板中输入 $\textbf{x}$ 和遮盖词 $\texttt{[MASK]}$ 的数量可以根据情况自己定义。下面我们展示了一些常见的 Prompt。比如对于文本对分类任务 NLI,模板中就会同时包含两个输入 $\textbf{x}1$ 和 $\textbf{x}2$:
| Task | Input $\textbf{x}$ | Pattern | verbalization |
|---|---|---|---|
| Sentiment | I love this movie. | $\textbf{x}$ The movie is $\texttt{[MASK]}$. | great fantastic … |
| Topics | He prompted the LM. | $\textbf{x}$ The text is about $\texttt{[MASK]}$. | sports science … |
| Intention | What is taxi fare to Denver? | $\textbf{x}$ The question is about $\texttt{[MASK]}$. | quantity city … |
| Aspect Sentiment | Poor service but good food. | $\textbf{x}$ What about service? $\texttt{[MASK]}$. | Bad Terrible … |
| NLI | $\textbf{x}1$ An old man with … $\textbf{x}2$ A man walks … |
$\textbf{x}1$? $\texttt{[MASK]}$, $\textbf{x}2$ | Yes No … |
| NER | $\textbf{x}1$ Mike went to Paris. $\textbf{x}2$ Paris |
$\textbf{x}1$ $\textbf{x}2$ is a $\texttt{[MASK]}$ entity. | organization location … |
| Summarization | Las Vegas police … | $\textbf{x}$ TL;DR: $\texttt{[MASK]}$ | The victim … A woman … … |
| Translation | Je vous aime. | French: $\textbf{x}$ English: $\texttt{[MASK]}$ | I love you. I fancy you. … |
可以看到,有时多个表意词可以对应同一个类别,例如对于情感分析任务来说,“excellent”、“fabulous”、“wonderful” 等 token 都可以用来表示积极极性。
2. Prompt 的问题
Prompt 方法最大的问题是——性能好坏完全依赖于模板以及表意与任务的匹配程度。研究 (Gao et al., 2021) 表明,即使是对模板进行轻微的调整(例如变换 $\texttt{[MASK]}$ token 的位置),都会对最终性能产生巨大的影响。
下表展示了使用不同 Pattern 完成同一个 SNLI 文本对分类任务的性能:
| Pattern | verbalization | Accuracy |
|---|---|---|
| $\textbf{x}_1$? $\texttt{[MASK]}$, $\textbf{x}_2$ | Yes/Maybe/No | 77.2 |
| $\textbf{x}_1$. $\texttt{[MASK]}$, $\textbf{x}_2$ | Yes/Maybe/No | 76.2 |
| $\textbf{x}_1$? $\texttt{[MASK]}$ $\textbf{x}_2$ | Yes/Maybe/No | 74.9 |
| $\textbf{x}_1$ $\textbf{x}_2$ $\texttt{[MASK]}$ | Yes/Maybe/No | 65.8 |
| $\textbf{x}_2$? $\texttt{[MASK]}$, $\textbf{x}_1$ | Yes/Maybe/No | 62.9 |
| $\textbf{x}_1$? $\texttt{[MASK]}$, $\textbf{x}_2$ | Maybe/No/Yes | 60.6 |
| Fine-tuning | - | 48.4 |
可以看到,在固定 Verbalizer 的情况下,只是把 $\texttt{[MASK]}$ token 放在 Pattern 末尾或者交换句子顺序,都会出现 >10% 的性能下降。同样地,固定 Pattern 变换表意也会产生不同的结果。下表展示了在相同 Pattern 下,改变 Verbalizer 对于情感分析任务 SST-2 的影响。
| Pattern | verbalization | Accuracy |
|---|---|---|
| $\textbf{x}$ It was $\texttt{[MASK]}$. | great/terrible | 92.7 |
| $\textbf{x}$ It was $\texttt{[MASK]}$. | good/bad | 92.5 |
| $\textbf{x}$ It was $\texttt{[MASK]}$. | cat/dog | 91.5 |
| $\textbf{x}$ It was $\texttt{[MASK]}$. | dog/cat | 86.2 |
| $\textbf{x}$ It was $\texttt{[MASK]}$. | terrible/great | 83.2 |
| Fine-tuning | - | 81.4 |
可以看到,当表意词与类别在语义上匹配时,最终的准确性就会更好,比如 great/terrible > good/bad > cat/dog。而如果我们交换表意词,比如 terrible/great,就会出现明显的性能下降。
有趣的是,cat/dog 的性能明显好于 dog/cat,因此 RoBERTa 模型似乎认为“cat”比“dog”更积极。
上面这些结果都表明 Prompt 方法的表现非常依赖于所选的模板和表意,因此如何设计一个好的模板以及对应的表意非常重要。
2.1 手工构建模板
目前,大部分工作依然采用手工方式构建模板和表意 (Schick & Schütze, 2020, 2021a,b) 。这不仅需要模板设计者掌握领域专业知识,并且还需要通过大量尝试来比较模板之间的性能差异(特别对于复杂任务)。而且即使是经验丰富的设计者也难以手工发现最优 Prompt。
2.2 自动构建模板
因此,有一些工作通过搜索或生成的方式来自动构建 Prompt。
尽管自动构建模板可以节省人工,但是依然需要耗费大量的计算以及时间成本,并且在最终性能上依然难以与人工构建 Prompt 相媲美。
早期工作通过梯度搜索 (Gradient-based Search)、运用语言模型 LM 对构建的候选模板打分 (Prompt Scoring) 以及模板挖掘 (Prompt Mining) 来选择最优 Prompt (Wallace et al., 2019; Davison et al., 2019; Jiang et al., 2020),后来 Shin et al. (2020) 还拓展了梯度搜索,使用下游应用的训练样本来自动搜索模板 tokens。特别地,基于给定的训练样本 $(\boldsymbol{x},\boldsymbol{y})$,Jiang et al. (2020) 在大规模语料库上搜索同时包含 $\boldsymbol{x}$ 和 $\boldsymbol{y}$ 的字符串,然后使用它们的中间词或依存路径来构建 Pattern,例如“$\textbf{x} \text{ middle words } \textbf{y}$”。
最近的工作则通过在(手工构建或挖掘出的)种子模板上运用模板解释 (Prompt Paraphrasing) 来生成更多的候选模板 (Yuan et al., 2021; Haviv et al., 2021),或者使用 T5 等生成模型直接生成模板 (Gao et al., 2021; Ben-David et al., 2021)。例如,Yuan et al. (2021) 和 Haviv et al. (2021) 分别通过替换词库中的短语和使用神经 Prompt 重写器来扩充模板,其中 Haviv et al. (2021) 先将输入 $\boldsymbol{x}$ 填充到模板后再进行解释,从而为每个输入都能生成不同的解释。
相比以替换为核心的模板解释方法,模板生成方法更加灵活并且几乎不需要人工参与。由于 T5 本身已经在填充缺失 span 任务上进行了预训练,因此 Gao et al. (2021) 通过指定模板 token 在 Pattern 中的位置来使用 T5 直接生成。例如,对于文本分类和文本对分类任务,可以构建 T5 模型的输入为:
\[\textbf{x} \rightarrow \texttt{[MASK]}_1 v_y \texttt{[MASK]}_2 \textbf{x} \\ \textbf{x} \rightarrow \textbf{x} \texttt{[MASK]}_1 v_y \texttt{[MASK]}_2 \\ \textbf{x}_1,\textbf{x}_2 \rightarrow \textbf{x}_1 \texttt{[MASK]}_1 v_y \texttt{[MASK]}_2 \textbf{x}_2\]其中,$\texttt{[MASK]}_1,\texttt{[MASK]}_2$ 是 T5 可以进行解码的特殊 token,用来生成模板 token,$v_y$ 是对应的表意词。由于 T5 可以在一个 mask 位置解码出多个 token,因此也不需要预先指定模板 token 的数量。对于每个输入 $\textbf{x}$,Gao et al. (2021) 都先通过 T5 生成一些候选 Pattern,最终通过验证集上的性能来选择最优 Pattern,如下图所示:

上图中最佳 Pattern 为:$\texttt{[MASK]}_1$ 生成“A”,$\texttt{[MASK]}_2$ 生成“one.”。不过,无论是生成大量候选 Pattern,还是对 Pattern 进行评估,都要耗费大量的时间和计算成本,因此这种方法并不实用 (Chen et al., 2021)。
2.3 多模板方法
此外,受集成学习同时运用多个模型的启发,还有一些工作尝试使用多个 Prompt 来共同完成任务,称为多模板学习 (multi-prompt learning)。常见的多模板方法有模板集成、模板增强、模板合成以及模板拆分, 如下图所示:

图中黄色框表示输入文本,蓝色框表示 prompt,红色框表示已回答模板 (answered prompt),绿色框表示子模板 (sub-prompt)。
-
模板集成 (Prompt Ensembling):使用多个 Prompt 共同对输入进行预测,如图 (a) 所示。相比单模板方法,模板集成可以利用不同 prompt 的互补优势;减轻构建模板的成本,毕竟要选出性能最优 prompt 非常困难;缓解对模板的依赖,使得性能更稳定。
最简单的模板集成就是将多个模板的预测概率进行平均作为最终的预测 (Jiang et al., 2020; Schick and Schütze, 2021a):
\[q_{\textbf{p}}(y\mid \textbf{x}) :=\frac{1}{K}\sum_{i}^K p(\texttt{[MASK]}=v_y\mid P_i(\textbf{x}))\]其中 $P_i(\cdot)$ 表示第 $i$ 个模板。还有一些工作给每个模板赋一个权重,然后通过加权求和得到最终的判断 (Jiang et al., 2020; Qin & Eisner, 2021)。当然,经典的投票表决法也可以用于模板集成 (Lester et al., 2021; Hambardzumyan et al., 2021)。
-
模板增强 (Prompt Augmentation):又称示例学习 (demonstration learning)。每次在输入 $\textbf{x}$ 时,还会提供一些已回答的 prompts 作为示例去引导 LM,如图 (b) 所示。例如我们要预测中国的首都,不是简单地输入“China’s capital is $\texttt{[MASK]}$ .”而是还会拼接一些填充好的模板作为示例:“Great Britain’s capital is London . Japan’s capital is Tokyo . China’s capital is $\texttt{[MASK]}$ .” (相当于提供了一些 few-shot 示例)。
但是,对示例的选择会极大地影响性能,从接近 SOTA 到接近随机猜测,并且示例的顺序同样非常重要 (Lu et al., 2022)。因此 Gao et al. (2021); Liu et al. (2022) 根据句子嵌入来采样示例,选择那些在嵌入空间中与输入接近的样本,还有一些工作提出打分方法来搜索最佳示例 (Lu et al., 2022; Kumar & Talukdar, 2021)。
-
模板合成 (Prompt Composition):适用于由多个子任务组合而成的任务。首先为每个子任务设计对应的子模板 (sub-prompt),然后基于所有的子模板定义一个合成模板 (composite prompt),如图 (c) 所示。
代表性的工作有 PTR (Han et al., 2021),把实体关系抽取拆分为“实体识别”和“关系分类”两个子任务,分别为这两个任务手工设计模板,然后根据逻辑规则将它们组合成一个完整的 Prompt。例如 PTR 把“person:parent”关系拆分成三个条件函数:
\[f_{e_s}(x,\text{person}) \wedge f_{e_s,e_o}(x,\text{'s parent was},y) \wedge f_{e_o}(y,\text{person}) \rightarrow \text{“person:parent”}\]其中 $f_{e_s}(\cdot,\cdot)$ 和 $f_{e_o}(\cdot,\cdot)$ 分别是判断 subject 和 object 实体类型的条件函数,$f_{e_s,e_o}(\cdot,\cdot,\cdot)$ 是判断实体之间关系的条件函数。这样就可以使用三个子模板来共同完成任务:

特别地,PTR 还在模板中添加了一些可学习的 token,这使得模板更具灵活性。
模板合成尤其适用于类别数很多的分类任务,它不仅可以降低模板设计难度,而且可以大幅减少需要的模板数量。
-
模板拆分 (Prompt Decomposition):有时候我们需要对一个输入预测出多个结果(例如序列标注),这时候直接为输入 $\textbf{x}$ 构建完整的模板非常困难。模板拆分将完整模板拆分为多个子模板 (sub-prompt),然后分别预测每一个模板的答案。图 (d) 展示了一个命名实体识别 (NER) 的例子,其首先将输入转换为 text span 组成的集合,然后应用子模板来预测每一个 span 的实体类型 (Cui et al., 2021)。
3. 模板必须为自然语言吗?
2.2 节中我们介绍了一些自动构建模板的方法,这些方法不仅需要大量的计算/时间成本,并且在性能上依然难以与人工构建模板相媲美。因此一些研究者产生了一个大胆的想法:既然构建模板如此麻烦,那么能不能让模板换一个形式,不再是由自然语言构成的文本呢?
如果放松模板为自然语言这一规定,而是将模板看成由一堆特殊 token 组成的序列,就可以直接在嵌入空间中进行 Prompting 了,这些 token 甚至都不必是 PLM 定义的词嵌入(没有对应的自然语言词语)。这种模板自身就是可学习变量的 Prompt 称为连续模板或软模板 (continuous prompts/soft prompts)。
3.1 再看模版定义
标准 Prompt 方法就是借助由自然语言构成的模版,将下游任务转化为与 PLM 预训练任务类似的形式,然后借助 PLM 模型进行预测。比如下图中通过 Cloze Prompt 实现情感分类和主题分类:


也可以使用 Prefix Prompt,将任务转换为一个生成任务来进行。不过由于语言模型是从左往右解码的,因此预测部分只能放在句末了。


因此,模版实际上就是添加在输入 $\textbf{x}$ 两边,由自然语言构成的前缀/后缀。那么问题出现了:
并不是。实际上我们并不关心模版长什么样,我们只需要知道模版由哪些 token 组成,它们的位置在哪里,能不能完成我们的下游任务,对应的表意是什么。对模版“自然语言”的要求,只是为了更好地实现一致性,但不是必须的。
于是,Liu et al. (2021a) 提出了 P-tuning,通过插入可训练的特殊嵌入来构建模版。比如:
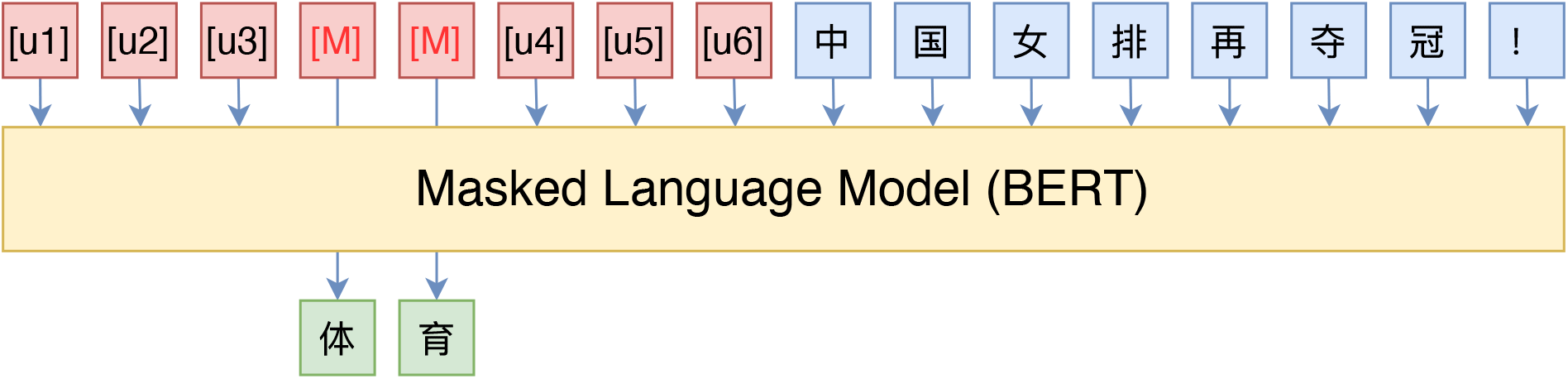
这里的 $\texttt{[u1]}$~$\texttt{[u6]}$ 代表 BERT 词表里边的 $\texttt{[unused1]}$~$\texttt{[unused6]}$,也就是使用几个从未见过的 token 来构成模板,token 的数目和位置都是超参数。然后,为了让模版发挥作用,我们用标注数据来调整这些特殊 token 的 Embedding。
3.2 如何优化 P-tuning
根据标注数据量的多少,P-tuning 的优化方式又分为两种情况。
-
数据较少:这种情况下,我们固定 PLM 的权重,只优化 $\texttt{[unused1]}$~$\texttt{[unused6]}$ 这几个特殊 token 的 Embedding,使得它们能够起到模版的作用。因为要学习的参数很少,所以训练起来很快,并且哪怕样本很少,也能把模版学出来,不容易过拟合。
当 PLM 非常大的时候,我们可能无法微调整个模型,而 P-tuning 可以选择只优化几个 token 的参数,这就给了我们一种在有限算力下调用大型 PLM 的思路。
-
数据充足:如果还按照第一种方案就会出现欠拟合,因为只有几个 token 作为可优化参数实在是太少了,此时就可以放开所有权重微调。但是这样就跟直接加个全连接微调很接近了,原论文的结果是这样做效果更好,可能是因为跟预训练任务更一致。
此外,现在的表意词(如上面的“不”、“体育”)都是人为选定的,那么它们可不可以也用 $\texttt{[unused*]}$ 代替呢?答案是可以,但也分两种情况考虑:在数据比较少的时候,人工来选定适当的表意词效果往往更好;在数据充足的情况下,表意词用 $\texttt{[unused*]}$ 效果更好,因为这时候模型的优化空间更大。
实际操作中,P-tuning 并不是随机初始化几个新 token 然后直接训练的,而是通过一个小型的 LSTM 模型把这几个 Embedding 算出来,并且将这个 LSTM 模型设为可学习的。Liu et al. (2021a) 认为通过 LSTM 编码后的 token 表示相关性更强,某种程度上来说更像“自然语言”,此外还能防止局部最优。
苏剑林 (2021) 认为,这里的 LSTM 是为了帮助模版的几个 token 更贴近自然语言,但这并不一定要通过 LSTM 生成,而且就算用 LSTM 生成也不一定能够实现这样的效果。更自然的方法是在训练下游任务的时候,不仅仅预测下游任务的表意词,还应该同时做其他 token 的预测。
比如,如果是 MLM 模型,那么也随机 mask 掉其他的一些 token 来预测;如果是 LM 模型,则预测完整的序列,而不单单是目标词。因为 MLM/LM 都是经过自然语言预训练的,所以可以粗略地认为能够很好完成重构的序列必然也是接近于自然语言的。苏剑林的实验显示加上这样的辅助目标确实提升了效果。
3.3 对模板作用的思考
P-tuning 最大的贡献在于放松了“模版由自然语言构成”这一要求,从而将其变成了可以通过梯度下降求解的连续参数问题,效果还更好。这种做法实际上突出了模版的本质——即模版的关键在于它是怎么用的,不在于它由什么构成。
那么为什么 P-tuning 会更好?比如全量数据下,大家都是放开所有权重,P-tuning 的方法依然比直接 finetune 要好,为啥呢?
事实上,大家已经对 BERT 加个全连接层的直接 finetune 做法“习以为常”了。很明显,不管是 PET 还是 P-tuning,其实都更接近预训练任务,而加个全连接层的做法,反而与预训练任务不一致。所以某种程度上来说,P-tuning 有效更加“显然”,反而是加个全连接层微调为什么会有效才值得疑问。
Saunshi et al. (2020) 曾试图回答这个问题,大致的论证顺序是:
- 预训练模型是某种语言模型任务;
- 下游任务可以表示为该种语言模型的某个特殊情形;
- 当输出空间有限的时候,它又近似于加一个全连接层;
- 所以加一个全连接层微调是有效的。
可以看到,假设主要是第 2 点——假设下游任务可以表达为类似 PET 的形式。这进一步说明了,PET、P-tuning 才是更自然的使用预训练模型的方式,加全连接层微调的做法其实只是它们的推论罢了。也就是说,PET、P-tuning 才是返璞归真、回归本质的方案,所以它们更有效。
除了 P-tuning 以外,另一项具有代表性的连续模板工作为 Prefix Tuning (Li & Liang, 2021)。其在输入前添加一个由任务相关连续向量组成的前缀,并且冻结 PLM 参数。在低数据 (low-data) 场景下,这种连续的基于前缀的学习比带有真实词语的 Prompt 更具优势。类似地,Lester et al. (2021) 在输入前添加特殊的 tokens 作为模板,并且直接训练这些 tokens 的表示。
4. Prompt 训练策略
虽然 Prompt 方法可以在没有任何训练数据的情况下完成任务 (zero-shot),但是往往性能较差。在大部分情况下,我们依然会使用语料来训练模型,包括拥有大量训练语料的全数据学习 (full-data learning) 以及只有少量标注语料的小样本学习 (few-shot learning)。
Prompt 方法中的可训练的参数来自于两个部分:PLM 以及模板。这时候我们就需要决定:1) 是否要微调 PLM 中的参数;2) 模板是否包含可学习参数。因此目前 Prompt 方法的训练策略可以分为以下 5 类:
| Strategy | PLM Params | Prompt Params | Example |
|---|---|---|---|
| Promptless Fine-tuning | Tuned | - | ELMo, BERT, BART |
| Tuning-free Prompting | Frozen | No | GPT-3, AutoPrompt, LAMA |
| Fixed-LM Prompt Tuning | Frozen | Yes | Prefix-Tuning, Prompt-Tuning |
| Fixed-prompt LM Tuning | Tuned | No | PET-TC, PET-Gen, LM-BFF |
| Prompt+LM Fine-tuning | Tuned | Yes | PADA, P-Tuning, PTR |
-
传统微调 (Promptless Fine-tuning):所有 PLM 参数利用下游任务反向传播来的损失梯度进行更新,例如流行的 BERT 和 RoBERTa 模型。但是这种训练方式在小数据集上容易过拟合或者训练非常不稳定。
-
优点:不需要设计模板,更新所有参数使得模型适用于包含大量训练数据的情况。
-
缺点:在小数据集上容易过拟合或者训练非常不稳定。
-
-
无训练 Prompting (Tuning-free Prompting):在不调整预 PLM 参数的情况下直接基于模板生成答案。当然也可以像 2.3 节模板增强中那样通过在模板中添加已回答模板来增强输入,这种结合无训练 Prompting 和模板增强的方式被称为情境学习 in-context learning (Brown et al., 2020)。典型的无训练 Prompting 有 LAMA (Petroni et al., 2019) 和 GPT-3。
-
优点:无需训练任何模型参数。适用于 zero-shot 场景。
-
缺点:需要精心构建模板才能取得较好的性能。尤其在 in-context learning 场景下,需要在预测时提供很多已回答的模板,因此速度很慢。
-
-
固定 LM 模板微调 (Fixed-LM Prompt Tuning):模板包含参数,冻结 PLM 参数,只训练模板参数。典型例子有 Prefix-Tuning (Li & Liang, 2021) 和 WARP (Hambardzumyan et al., 2021)。
- 优点:可以保持 PLM 中蕴含的知识,一般比无训练 Prompting 性能更好。适用于 few-shot 场景。
- 缺点:无法用于 zero-shot 场景。在包含大量训练数据的场景下无法学习到高效的表示。模板需要设置超参数,并且通常不是人类可理解或可操作的。
-
固定模板 LM 微调 (Fixed-prompt LM Tuning):使用固定参数的模板,训练时只需要微调 PLM 参数。这是目前最常见的 Prompt 方法,通过将包含 $\texttt{[MASK]}$ token 的文字模板应用到每个训练和测试样本上来完成任务,例如 PET-TC (Schick & Schütze, 2021a), PET-Gen (Schick & Schütze, 2020) 和 LM-BFF (Gao et al., 2021)。
- 优点:通过模板和表意说明了任务的目的,从而可以高效地进行学习,尤其适用于 few-shot 场景。
- 缺点:需要构建模板以及表意,并且在某个下游任务上微调的 PLM 可能无法有效应用于其他任务。
是否一定需要模板和表意?
Logan IV et al. (2021) 发现在微调 LM 的情况下,我们甚至可以省略模板,例如直接连接输入和 mask 字符的空模板 (null prompt) “$\textbf{x } \texttt{[MASK]}$”也可以取得不错性能,比传统直接微调 $\texttt{[CLS]}$ 表示会好得多。此外,Sun et al. (2021) 还通过将人工模板中 $\texttt{[MASK]}$ token 对应的表示直接送入到任务相关的分类器而不是 MLM 中来省略表意设计。
-
Prompt+LM 微调 (Prompt+LM Tuning):模板包含参数,并且和 PLM 中的全部或部分参数一起训练。典型的例子有 PADA (Ben-David et al., 2021) 和 P-Tuning (Liu et al., 2021a)。这种方式与传统微调非常接近,只是通过 Prompt 在模型训练开始时提供额外的引导。
- 优点:最灵活的 Prompt 方法,适用于包含大量训练数据 (high-data) 的场景。
- 缺点:需要对模型中所有的参数进行训练和存储,可能在小数据集上过拟合。
5. Prompt 的应用
5.1 分类任务
文本分类是 NLP 领域最常见的任务类型,因此相关的 Prompt 探索也最多。例如,Yin et al. (2019) 首先构建了一个类似“the topic of this document is $\texttt{[MASK]}$”的模板,然后将其送入到预训练 MLM 模型进行槽填充 (slot filling)。
- 文本分类:先前的工作大多采用遮盖模板 (cloze prompts) 来进行,并且专注于如何构建模板 (Gao et al., 2021; Hambardzumyan et al., 2021; Lester et al., 2021) 和表意 (Schick and Schütze, 2021a; Schick et al., 2020; Gao et al., 2021)。这些方法大多针对 few-shot 场景,并且采用 Fixed-prompt LM Tuning 方式训练模型。
- 自然语言推理 (NLI):旨在判断两个句子之间的关系。与文本分类任务类似,遮盖模板 (cloze prompts) 同样是使用最广泛的 Prompt 方法 (Schick and Schütze, 2021a)。在模板构建方面,研究者通常关注 few-shot 学习场景下的模板搜索,并且表意词是从词汇表中手动预选的。
5.2 信息抽取
与分类任务可以直观地构建 cloze 问题不同,信息抽取任务在构建模板时通常需要一些技巧。
-
实体关系抽取:Chen et al. (2022) 首次探索了 Fixed-prompt LM Tuning 在关系抽取领域的应用,并提出了关系抽取 Prompt 方法的两个主要挑战:1) 相比分类任务标签空间更大(常见的关系抽取有 80 类标签),因此构建对应的表意难度更高;2) 对于关系抽取,输入句子中 token 的重要性可能不同(例如实体更加重要),而默认情况下模板平等地对待每一个 token。对此,Chen et al. (2022) 对于问题 1) 构建了面向任务的提示模板,对于 2) 使用一些特殊的标记(例如 $\texttt{[E]}$)在模板中标记出实体。
类似地,Han et al. (2021) 通过我们在 2.3 小节中介绍的多模板合成 (multiple prompt composition) 方式来引入实体类型信息;Zhou & Chen (2021) 比较了向模板中添加实体信息的不同方法。
-
序列标注:序列标注的预测对象是一个 token 或者一个 span,而不是整个输入文本,并且 token 标签之间存在潜在的联系。目前如何将 Prompt 方法应用于序列标注任务仍然处于探索阶段。Cui et al. (2021) 提出了一个基于 BART 的模板 NER 方法,其首先列举所有可能的文本片段,然后使用人工模板判别每个片段的标签。例如对于输入“Mike went to New York yesterday”,可以通过模板“Mike is a $\texttt{[Z]}$ entity”来判断实体“Mike”的实体类型。
5.3 自动问答
自动问答任务 (QA) 负责基于上下文信息回答指定的问题,根据形式可以分为:
- 抽取式 QA (extractive QA):答案包含在上下文中,直接从文档中抽取答案,例如 SQuAD;
- 多选 QA (multiple-choice QA):从多个给定的选项中选择答案,例如 RACE;
- 无约束 QA (free-form QA):直接返回答案文本,并且对答案文本格式没有任何限制,例如 NarrativeQA。
传统方法需要为每种 QA 形式设计对应的模型框架,而 Prompt 方法可以使用统一的框架来解决所有这些 QA 问题。例如 Khashabi et al. (2020) 将多种 QA 任务都重新定义为文本生成问题,然后通过微调预训练 seq2seq 模型(例如 T5)以及合适的模板来完成。Jiang et al. (2020) 详细分析了使用 seq2seq PLM (例如 T5, BART, GPT2)的多种模板方法,发现这些 PLM 在 QA 任务上的概率并不能很好地预测模型是否正确。
5.4 文本生成
文本生成有各种各样的任务形式,大多数都是在某些信息的约束下进行生成。将 Prompt 方法应用于文本生成任务非常简单,只需要结合prefix prompt 和 auto-regressive PLM 就可以完成大部分任务。Radford et al. (2019) 首次使用类似“translate to french, $\textbf{x}$, $\texttt{[MASK]}$”的模板完成文本摘要、机器翻译等任务,之后越来越多的工作尝试将其他 Prompt 训练策略应用于文本生成任务。例如 Brown et al. (2020) 提出了 in-context learning,使用多个已回答模板样例来增强人工模板。Schick and Schütze (2020) 使用人工模板在 few-shot 文本摘要任务上探索了 Fixed-prompt LM tuning 方法的有效性。Li and Liang (2021) 研究了在 few-shot 场景下,将 Fixed-LM Prompt Tuning 用于文本摘要和 data-to-text 生成的表现。Dou et al. (2021) 探索了 Prompt+LM Tuning 在文本摘要任务上的表现。
6. 附录
在下表中我们展示了一些常见的模板和表意。其中 $\textbf{x}$ 表示输入,$\texttt{[MASK]}$ 表示特殊的答案 token,$\mathcal{V}$ 表示 PLM 的词表:
| Task | Pattern | verbalization |
|---|---|---|
| Fact Probing | Adolphe Adam died in $\texttt{[MASK]}$. iPod Touch is produced by $\texttt{[MASK]}$. The official language of Mauritius is $\texttt{[MASK]}$. |
$\mathcal{V}$ |
| Text Classificatin | Which of these choices best describes the following document? ”[Class A]”, ”[Class B]”, ”[Class C]”. $\textbf{x}$ $\texttt{[MASK]}$ How is the text best described? : ”[Class A]”, “[Class B]” , or “[Class C]”. $\textbf{x}$ $\texttt{[MASK]}$ This passage is about $\texttt{[MASK]}$: $\textbf{x}$ $\textbf{x}$. Is this review positive? $\texttt{[MASK]}$ $\textbf{x}$ It was $\texttt{[MASK]}$. |
[Class A], [Class B], [Class C] [Class A], [Class B], [Class C] [Class A], [Class B], [Class C] Yes, No great, terrible |
| Natural Language Inference | $\textbf{x}_1$? $\texttt{[MASK]}$, $\textbf{x}_2$ $\textbf{x}_1$ $\texttt{[MASK]}$, $\textbf{x}_2$ |
Yes, No, Maybe |
| Commonsense Reasoning | The trophy doesn’t fit into the brown suitcase because $\texttt{[MASK]}$ is too large. Ann asked Mary what time the library closes, because $\texttt{[MASK]}$ had forgotten. |
trophy, suitcase Ann, Mary |
| Linguistic Knowledge Probing | A robin is a $\texttt{[MASK]}$. A robin is not a $\texttt{[MASK]}$. New is the opposite of $\texttt{[MASK]}$. |
bird, tree bird, tree old, young, current |
| Named Entity Recognition | $\textbf{x}$ [Span] is a $\texttt{[MASK]}$ entity. $\textbf{x}$ [Span] is not a named entity. $\textbf{x}$ The entity type of [Span] is $\texttt{[MASK]}$. $\textbf{x}$ The entity type of [Span] is none entity. |
person, location, organization, miscellaneous |
| Question Answering | [Question] [Passage] $\texttt{[MASK]}$ [Passage] According to the passage, [Question] $\texttt{[MASK]}$ Based on the following passage, [Question] $\texttt{[MASK]}$. [Passage] |
- |
| Summarization | $\textbf{x}$ Summary: $\texttt{[MASK]}$ $\textbf{x}$ TL;DR: $\texttt{[MASK]}$ $\textbf{x}$ In summary, $\texttt{[MASK]}$ |
- |
| Machine Translation | French: [French sentence] English: $\texttt{[MASK]}$ A French sentence is provided: [French sentence] The French translator translates the sentence into English: $\texttt{[MASK]}$ [French sentence] = $\texttt{[MASK]}$ |
- |
参考
[1] 苏剑林《P-tuning:自动构建模版,释放语言模型潜能》, 2021.
[2] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. arXiv:2107.13586, 2021b.
[3] Eyal Ben-David, Nadav Oved, Roi Reichart. PADA: Example-based Prompt Learning for on-the-fly Adaptation to Unseen Domains. arXiv:2102.12206, 2021.
[4] Tom B Brown, Benjamin Mann, Nick Ryder, et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems 33 (NeurIPS), 2020.
[5] Xiang Chen, Xin Xie, Ningyu Zhang, Jiahuan Yan, Shumin Deng, Chuanqi Tan, Fei Huang, Luo Si, Huajun Chen. AdaPrompt: Adaptive Prompt-based Finetuning for Relation Extraction. arXiv:2104.07650v1, 2021.
[6] Xiang Chen, Ningyu Zhang, Xin Xie, Shumin Deng, Yunzhi Yao, Chuanqi Tan, Fei Huang, Luo Si, Huajun Chen. KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction. In WWW 22: Proceedings of the ACM Web Conference, 2022.
[7] Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 2019.
[8] Leyang Cui, Yu Wu, Jian Liu, Sen Yang, Yue Zhang. Template-Based Named Entity Recognition Using BART. In Findings of the Association for Computational Linguistics (ACL-IJCNLP), 2021.
[9] Joe Davison, Joshua Feldman, Alexander Rush. Commonsense Knowledge Mining from Pretrained Models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019.
[10] Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi, Zhengbao Jiang, Graham Neubig. GSum: A General Framework for Guided Neural Abstractive Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021.
[11] Tianyu Gao, Adam Fisch, Danqi Chen. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP), 2021.
[12] Karen Hambardzumyan, Hrant Khachatrian, Jonathan May. WARP: Word-level Adversarial ReProgramming. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021.
[13] Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, Maosong Sun. PTR: Prompt Tuning with Rules for Text Classification. In arXiv:2105.11259, 2021.
[14] Adi Haviv, Jonathan Berant, Amir Globerson. BERTese: Learning to Speak to BERT. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021.
[15] John Hewitt, Christopher D. Manning. A Structural Probe for Finding Syntax in Word Representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019.
[16] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly. Parameter-Efficient Transfer Learning for NLP. arXiv:1902.00751, 2019.
[17] Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, Hannaneh Hajishirzi. UNIFIEDQA: Crossing Format Boundaries with a Single QA System. In Findings of the Association for Computational Linguistics (EMNLP-Findings), 2020.
[18] Sawan Kumar, Partha Talukdar. Reordering Examples Helps during Priming-based Few-Shot Learning. In Findings of the Association for Computational Linguistics (ACL-IJCNLP), 2021.
[19] Xiang Lisa Li, Percy Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021.
[20] Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, Weizhu Chen. What Makes Good In-Context Examples for GPT-3? In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, 2022.
[21] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, Jie Tang. GPT Understands, Too. arXiv:2103.10385, 2021a.
[22] Robert Logan IV, Ivana Balazevic, Eric Wallace, Fabio Petroni, Sameer Singh, Sebastian Riedel. Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models. In Findings of the Association for Computational Linguistics, 2022.
[23] Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, Pontus Stenetorp. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 2022.
[24] Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig. How Can We Know What Language Models Know? In Transactions of the Association for Computational Linguistics, 2020.
[25] Brian Lester, Rami Al-Rfou, Noah Constant. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021.
[26] Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander Miller. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019.
[27] Guanghui Qin, Jason Eisner. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, 2021.
[28] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Language models are unsupervised multitask learners.
[29] Nikunj Saunshi, Sadhika Malladi, Sanjeev Arora. A Mathematical Exploration of Why Language Models Help Solve Downstream Tasks. arXiv:2010.03648, 2020.
[30] Timo Schick, Hinrich Schütze. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2021a.
[31] Timo Schick, Hinrich Schütze. It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021b.
[32] Timo Schick, Helmut Schmid, Hinrich Schütze. Automatically Identifying Words That Can Serve as Labels for Few-Shot Text Classification. In Proceedings of the 28th International Conference on Computational Linguistics, 2020.
[33] Timo Schick, Hinrich Schütze. Few-Shot Text Generation with Pattern-Exploiting Training. arXiv:2012.11926, 2020.
[34] Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, Sameer Singh. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020.
[35] Xiaodi Sun, Sunny Rajagopalan, Priyanka Nigam, Weiyi Lu, Yi Xu, Belinda Zeng, Trishul Chilimbi. DynaMaR: Dynamic Prompt with Mask Token Representation. In arXiv:2206.02982, 2022.
[36] Jesse Vig. A multiscale visualization of attention in the transformer model. arXiv preprint arXiv:1906.05714, 2019.
[37] Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, Sameer Singh. Universal Adversarial Triggers for Attacking and Analyzing NLP. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019.
[38] Chenguang Wang, Xiao Liu, Dawn Song. Language Models are Open Knowledge Graphs. arXiv:2010.11967, 2020.
[39] Weizhe Yuan, Graham Neubig, Pengfei Liu. BARTScore: Evaluating Generated Text as Text Generation. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021), 2021.
[40] Wenxuan Zhou, Muhao Chen. An Improved Baseline for Sentence-level Relation Extraction. arXiv:2102.01373, 2021.